*Enterprise-IoT
*Smart Machine 사례연구
*Middleware 사례연구
*AI·Big Data 사례연구
*IoT 사례연구
*Smart Thinks 사례연구
*정부정책동향 사례연구
*K-SmartFactory
*Hidden Champion
*카드뉴스
*국내외 동향 리포트

이 문서의 번역:
3. [빅] 데이터와 프로세스 관리
이 기술 개요의 첫 번째 파트는 주로 자산 관련 자료에 강한 초점을 맞춰온, loT내에서 관리되어온 다른 종류의 데이터를 살펴본다. 또한 우리는 어떤 데이터 관리 기술이 각 프로젝트의 시나리오에 적합한지 이야기할 것이다.
두 번째 파트에서는 어떻게 프로세스 관리가 loT 솔루션의 기능적인 면을 간소화시키고, 활용하고, 부분적으로 자동화하는 역할을 할 수 있을지 살펴볼 것이다. 또한 어떤 종류의 프로세스 관리 기술이 loT내의 어떤 프로세스에 적합할지, 그리고 이것이 첫 번째 파트에서 소개된 다른 종류의 데이터와 어떻게 연관될 수 있을지 논의할 것이다. 특히, 어떻게 다른 종류의 loT 사건과 분석적인 결과가 프로세스를 발생시키거나 신호를 보낼 수 있을지 이해하고자 한다.
I. [빅] 데이터 관리
빅데이터는 가장 중요한 loT 실현 기술 중 하나로 여겨진다. 이 장에, 우리는 M2M과 loT 어플리케이션을 위한 빅(그리고 그다지 ‘크지’ 않은) 데이터 관리에 대해 이야기할 것이다. 이것은 복잡한 주제이고 두루 적용되도록 만든 해결책이 없기 때문에, 우리는 다른 복잡성의 시나리오부터 이야기해나감으로써 점차적으로 대화를 구성해나갈 것이다. 그러나, 이에 다다르기 전에, 우리는 빅데이터 동향에서 가장 존경받는 권위자인 Cloudera의 설립자이자 최고 전략 전략책임자인 Mike Olson과 얘기함으로써 발판을 마련할 것이다.
Dirk Slama: Mike, Cloudera는 가장 널리 사용되는 빅데이터 체계 중 하나인 Apache Hadoo를 담당하고 있습니다. 당신이 본 것 중 가장 흥미로운 당신의 기술을 사용한 loT 사용 경우에 대해 설명해주실 수 있습니까?
Mike Olson: 그럼요. 당신이 CERN의 Large Hadron Collider(LHC)를 당신에 책에서 케이스 스터디 중 하나로 언급했습니다. 그리고 어떻게 LHC가 단지 광대한 양의 센서 데이터를 수집했을 뿐만 아니라, 실험으로부터 데이터를 위한 효과적이고 여러 단계로 작동하는 정보 루트를 만들어나가고 있는지도요. 밝혀졌듯이, Nebraska-Lincoln대학교에서 이런 작동 정보 루트의 2단계에서 적어도 연구 시설들 중 하나는 Hadoop을 이용하고 있습니다. 그들은 CERN에서 입자 충돌로부터 발생되는 방대한 양의 데이터에서 심화된 물리 분석을 이행하기 위해 이것을 사용하고 있습니다.
또한 많은 흥미로운 연구들이 존재합니다. 예를 들어, 스마트 그리드는 분명히 빅테이터 기술을 이용한 중요한 loT 어플리케이션입니다. 그리고 우리는 Hadoop이 많은 회사들에서 사용되고 있다는 것을 압니다. 좋은 예시는 Opower로, 그들의 자동계량으로부터 스마트 그리드 관찰 스트리밍을 사용, 관찰 및 분석하길 원하는 유틸리티에 그들의 서비스를 판매하고 있습니다. 자동 계량은 매 6초마다 관찰을 기록하고 있으며, 이는 수집하기 위해 사용했던 한달 마다 측정했던 것보다 대단히 많습니다. 이것은 그들이 하루 동안 요구되는 잘 정제된 신호를 성립한다는 것을 의미합니다. 그들은 심지어 세탁기를 켜거나 냉장고가 켜졌다는 것 같은 명확한 사건이 언제 발생하는지도 결정할 수 있습니다. 예를 들어, 그들은 실제 시간에서 요구를 관찰할 수 있고, 이런 관찰의 변동을 예측합니다. 이는 단지 스마트 그리드 활동에 기초하지 않고, 기창 예측, 보고 그리고 다가오는 기념일이나 이벤트에 기초하기도 합니다. 그들은 심지어 요구를 관리하기 위해 예를 들면 고객이 그들의 사용이 이웃의 비교되는 것을 알게 하고, 사람들이 경쟁을 하도록 유도하는 것과 같이, 게임화(gamification- 게임과 무관한 웹사이트나 어플리케이션에서 게임과 연관된 개념을 활용하는 것)를 이용할 수도 있습니다.
매우 다양한 범위의 사용 케이스가 있지만, 보통 모든 이런 데이터들은 기계 도량에서 기계와 센서에 의해 발생합니다. 오래된 기술을 사용하여 이것을 모으고 분석하는 것은 도전입니다. 거대하고, 도량을 벗어난 기반은 이런 자료의 과정과 분석을 훨씬 저렴하게 만들어줍니다.
Dirk Slama: 그래서, 이전 세대의 컴퓨터 사용과 데이터 관리에 의해 직면되지 않았던 어떤 도전을 loT가 선사합니까?
Mike Olson: 제 개인적인 견해는 우리는 오직 매우 이른 단계의 loT 데이터 흐름만을 보고 있으며, 이런 데이터 흐름들은 거의 압도적입니다. 한 달에 한번과 1분에 10번 읽은 것으로부터 스마트 그리드로부터 스트리밍되는 정보의 양을 생각해 봅시다. 이것은 한 달 동안 미터당 150,000배 많은 관찰 입니다. 이런 데이터 용량은 가속화되도록 보장되어 있습니다. 미래에, 우리는 더 많은 기기로부터 더 잘 정제된 데이터를 모으고 있을 것입니다.
샌프란시스코 도시를 살펴보면, 일부 사람들은 도시 내에 스마트폰이나 차뿐만 아니라, 공기압, 온도, 진동 등을 측정하는 도시의 높은 빌딩들과 같이 많은 곳에서 사용하는 센서가 20억개라고 측정합니다. 현재 이런 센서에서 가장 흥미로운 점은 그들의 대부분이 네트워크에 연결되어있지 않다는 것입니다. 저는 앞으로 반 세기 내로 그들의 대부분이 네트워크에 연결되고, 그런 기기 들은 네트워크나 메쉬 연결 센서로 교환될 것이라고 생각합니다. 그리고 이것은 확실한 쓰나미 데이터를 가져올 것입니다. 그래서 이러한 데이터를 측정하고, 가공하고, 요약하고, 관리하고 분석할 수 있는 시스템을 고안하는 것이 IT의 큰 도전입니다. 우리는 우리가 보려던 것과 같은 정보의 호수를 한번도 본 적이 없습니다.
Dirk Slama: 그래서, loT를 현실로 만드는 데이터 관리에 핵심 발전이 있을 것입니까?
Mike Olson: 우리는 오늘날 10년전에는 없던 계산 플랫폼과 도량을 넘어선 저장을 만들고 있습니다. 우리는 그것의 도량에서 정보를 모으지 않았고, 우리가 지금 하는 것과 같이 분석하려고 하지 않았기 때문에 그들을 필요로 하지 않았었습니다. 기계에서 발생한 데이터의 도래가 우리에게 어떻게 데이터를 측정, 저장, 가공해야 하는지 재고하게끔 하고 있습니다. 매우 대규모의 유사한 계산 시스템을 만드는 것은 현재 매우 흔한 일입니다. 우리가 만일 앞으로 5년에서 10년의 발전을 살펴본다면, 소프트웨어의 상태는 계속 개선될 것입니다. 우리는 더 나은 분석 알고리즘, 도량을 넘어선 저장 아키텍처를 갖고 있을 것이며, 적은 디스크 공간을 관리할 수 있을 것입니다. 왜냐하면 우리는 어떻게 데이터를 입력하고 복제해야 하는지 더 잘 알고 있을 것이기 때문입니다.
그러나 제가 생각하기로 가장 흥미로운 것은 하드웨어에서의 발전입니다. 모바일 기기나 일반적인 환경에서 네트워크와 연결된 센서들의 계속 확산하거나 폭발적으로 증가할 것입니다. 이는 많은 양의 새로운 데이터를 생산할 것입니다. Intel의 Atom Chip-Line이나 다른 판매 회사의 비슷한 것들을 생각해 보십시오. 데이터 측정/저장/분석 면에서, 우리는 도량을 넘어선 기반이 더 잘 구축된 칩들을 볼 것입니다. 메모리 밀도는 당연히 증가할 것이며, 우리는 많은 어플리케이션에서 디스크를 대체하는 고체 드라이브를 사용할 것입니다. 칩의 단계에서 네트워킹 접속은 더욱 빠르고 흔해질 것이며, 주로 칩 레벨에서 가능한 전기를 이용한 네트워크를 대신해서 광학 저장을 사용할 것입니다. 메모리에 디스크인 저장에서의 상대적인 잠복은 이동할 것이고, RAM에 고체 상태의 디스크는 미래에 더 보편적인 방법이 될 것입니다. 광학 네트워크의 속도는 저장공간을 더욱 접근 용이하게 이동시킬 것입니다. 그래서 저는 하드웨어 단계에서 이전에 가능했던 그 어떤 것보다 더 많은 데이터와 함께할 소프트웨어를 실현할 많은 혁명을 보게 될 것이라고 생각합니다.
Dirk Slama: 빅데이터를 사용하는 loT 솔루션을 구축하고 싶은 회사들에게 가장 큰 위험 요소은 무엇입니까? 어떻게 이런 위험 요소를 경감시킬 수 있습니까?
Mike Olson: 데이터를 측정하고, 정제하고 분석하는 기반뿐만 아니라, 센서 네트워크의 도량을 넘어선 확산과 같은 종류의 데이터를 발생하는 기술은 새롭습니다. 우리의 경험은 이 개념의 작은 범위에서 입증에서 시작하는 것이 현명하다는 것이었습니다. 수백만 개의 기기를 대신해서, 아마도 수천 개의 기기에서 시작해 보십시오. 그리고 이를 처리할 수 있는 측정 및 정제 기반을 만드십시오. 이렇게 함으로써 당신은 이것이 잘 작동하는지 체크할 수 있으며, 어떻게 이런 시스템이 작동하고, 무엇을 할 수 있는지에 관해 당신의 사람이나 조직을 교육시킬 수 있습니다. 이것들은 새로운 기술이며 새로운 기술의 채택은 성공적인 배치를 위해 교육과 새로운 과정을 요구합니다. 무한한 범위의 loT를 실행하기 전에 작은 범위에서 이것을 배우는 것은 중요합니다.
우리는 loT기술에 매료된 많은 사람들과 이야기합니다. 그들은 그것 자체로의 빅데이터에 흥분합니다. 그들은 우리가 일하기에 좋지 않은 사람들입니다. 왜냐하면 그들은 근본적으로 사업적인 문제에서 동력을 얻지 않기 때문입니다. 당신이 loT가 왜 중요한지에 대해 생각하기 시작할 때, 이는 매우 중요합니다. 어떤 질문에 당신은 센서 데이터 스트리밍으로 답하고 싶습니까? 어떤 비즈니스 문제를 해결하고 싶습니까? 어떤 최적화를 만들어내고 싶습니까? 그리고 이런 문제들을 제기하기 위한 당신의 시스템을 고안하십시오. 저는 새로운 기술을 활용하고 싶은 엔지니어들의 ‘샤이니 오브젝트 신드롬’을 가진 사람들 중 하나이지만, 그런 프로젝트들은 보통 명확한 기준이 없기 때문에 실패합니다.
Dirk Slama: 당신에게 빅데이터 기술을 사용할 때라고, 혹은 사용하지 말라고 말해주는 명확한 지표가 있습니까?
Mike Olson: 만약 당신이 전통적인 거래 프로세싱이나 OLAP 작업량을 갖고 있다면, 우리는 당신에게 Oracle, SQL Server, Terra Date등을 가리킬 것입니다. 왜냐하면 이런 시스템들은 저런 형태에서 작업하도록 발전했기 때문입니다. 새로운 데이터 양이나 새로운 분석 작업은 빅데이터 기술이 가장 잘 적용될 수 있는 곳입니다. 목표가 ‘우리는 존재하던 기반을 치워 버리고 이것을 Hadoop으로 교체하고 싶어요’일 때, 우리는 보통 그런 기회를 떠납니다. 이런 것은 잘 적용될 수 없습니다. 만약 당신이 새로운 문제나 사업 추진, 그리고 새로운 데이터 양를 만나면, 이들이 가장 성공적인 경우입니다. 떼어내고 교체하고자 하는 거대하고 눈이 먼 욕구는 절대 성공하지 않습니다.
Dirk Slama: 이런 지표들을 정량화할 수 있습니까? 빅데이터 기술을 요구하기 위한 데이터는 얼마나 커야 합니까?
Mike Olson: 산업이 빅데이터에 대해 이야기할 때, 그들은 항상 양, 다양성, 속도에 대해서 이야기 합니다. 이것은 당신이 매우 큰 양의 데이터를 가질 수 있고, 당신이 절대 한번에 모아볼 수 없었던 매우 다른 종류의 데이터를 가질 수 있고, 혹은 당신이 격정적인 속도로 도착하는 데이터를 가질 수 있다는 것을 의미합니다. 우리가 볼 때 Vs에 적합하지 않지만, 당신이 반드시 이용해야 할 분석 알고리즘인 하나의 기준이 있습니다. 이것은, 당신이 데이터에 이행하고 싶은 계산 방식은 무엇인가? 입니다. 때때로 당신이 적당한 양의 데이터를 기반으로 매우 많은 계산을 필요로 한다면, Hadoop같은 도량을 넘어서는 기반은 타당합니다. 양, 다양성, 속도 혹은 컴퓨터를 사용한 복잡함 필요조건들 중 하나만 만족시키면 빅데이터 기반을 매력적으로 만들기에 충분합니다. 우리의 경험해서, 만약 당신이 저런 필요 조건들 중 두 개 이상을 갖고 있다면, 새로운 플랫폼은 치명적입니다.
Dirk Slama: 빅데이터와 loT의 이행과 전략을 개발하고 있는 독자들에게 해주고 싶은 충고가 있습니까?
Mike Olson: 함께 일하는 조직에 하는 제 일관된 충고는 사업을 위해서 성공적인 결과가 의미 있는 한, 두 개의 사용 사례를 갖고 적정한 범위에서 공격해 보라는 것입니다. 이로 인해 당신은 필요한 기술을 얻고, 기술이 실제로 문제를 해결해 준다는 것을 입증할 수 있을 것입니다. 한번 이를 해두면, 주어진 기반에서 큰 범위도 간단하게 일관적인 가격으로 적용되고, 성공적일 것입니다.
Dirk Slama: 누가 loT와 빅데이터로부터 가장 많이 그리고 적게 얻을 수 있는 위치에 있습니까?
Mike Olson: 제 진심 어린 확신은 데이터는 실질적으로 모든 인간의 노력 범주에서 변형된다는 것입니다. 그래서, 당신과 제 일생에서, 우리는 암을 위한 치료법을 찾을 것입니다. 왜냐하면 우리는 이전에 할 수 없었던 방법으로 유전적이고 환경적인 데이터를 분석할 수 있기 때문입니다. 농업 사회에서 깨끗한 물과 에너지의 생산과 분배로 우리는 70억 대신 90억명의 사람들에게 배급할 수 있는 더 조밀하고 나은 농작물을 키울 수도 있습니다. 모든 노력에서, 데이터는 효율성을 제공할 것입니다. 만약 기업들이 기회를 놓친다면, 그들은 경쟁에서 질 수도 있습니다.
최근 사생활과 Edward Snowden, NSA에 관하여 많은 논란이 있었습니다. 제가 가진 하나의 염려는 이런 예시들 때문에 우리가 부당한 반발을 가질 수 있다는 것입니다. 그러나 예를 들어 우리가 매우 정교하게 학생의 행동을 관찰할 수 있다면, 그리고 각 학생의 학습 양식에 맞춰 수업을 고안할 수 있다면 얻을 수 있는 장점에 대해서 생각해봅시다. 우린 그 어느 때보다도 빠르고 효과적으로 배울 수 있는 똑똑한 사람들을 갖게 될 것입니다. 우리가 가져올 건강관리의 질에 관해서 생각해 보십시오.
사생활은 중요하고, 앞으로도 중요할 것입니다. 우리는 사생활을 타당하게 보장하는 정교한 정책, 의미 있는 법과 처벌이 필요합니다. ‘데이터 지니’는 병에서 나온 것 과 같습니다. 저는 우리가 이를 다시 되돌릴 수 있다고 생각하지 않습니다. 보통, 저는 데이터의 생산과 수집을 축소하기 위해 시도하는 것은 실수라고 생각합니다. 왜냐하면 저는 이것이 우리 사회에서 대단히 좋은 기회라고 믿기 때문입니다.
IoT 데이터 유형 및 분석 유형
파트 2(“Ignite | IoT 방법론”)의 Plan/Build/Run 부분에서 다뤘듯이, 배포된 loT 어플리케이션 지형 내에서 다른 데이터 종류들 사이의 관계와 분배를 이해하는 것은 중요하다. 아래의 자료는 loT 환경 내에서 발견되는 가장 보편적인 데이터 종류의 개요를 제공한다. 멀리 떨어진 자산으로부터 오는 데이터는 보통 미터 데이터, 센서 데이터, 사건 데이터 및 비디오 데이터 같은 멀티미디어 데이터를 포함한다. 자산에 업로드된 데이터는 대부분 구성 데이터, 작업 지시, 기상 예측 같은 의사결정 맥락, 그리고 다양한 멀티미디어 파일을 포함한다. 말미에서, 멀리 떨어진 자산으로부터 오는 데이터들은 보통 정해진 loT나 M2M 데이터 저장소에서 관리된다. 이 저장소들은 미터 기록의 모음 같은 시간 연속 데이터뿐만이 아니라, 기본적인 자산 데이터와 기기데이터, 상태 데이터, 상태 변화 기록 등을 포함한다. 쓸만한 여러 종류들로 이루어진 기업 어플리케이션 지형의 경우와 같이, 일부는 불필요할 수 있는 자산 관련 데이터를 포함한 다른 어플리케이션이 대부분이라는 것은 아무런 가치가 없다. 예를 들어, ERP 시스템은 고객 계약 데이터를 비롯하여 판매 시간에 제품 배치에 관련된 모든 데이터를 포함한 Asset Master Data를 갖고 있는 경향이 있다. 하나 이상의 티켓 관리 시스템이 구체적인 자산에 관련된 고객 문의들을 포함한다. 이런 데이터들을 하나의 전체적인 자산의 관점으로 합치는 것은 보통 도전적인 일이다. 덧붙여, 다른 시스템들에는 고객 거래 기록, 고객의 사회적 데이터, 상품 데이터를 포함한 많은 관련된 데이터들이 있을 것이다.
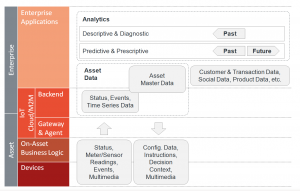 Data & analytics in the context of Enterprise IoT
Data & analytics in the context of Enterprise IoT
이 데이터를 기반으로 효율적인 어플리케이션을 구축하는 것은 이질적인 기업 어플리케이션 랜드스케이프에서 만큼이나 어려우며, EAM (기업 아키텍처 관리), EAI (기업 어플리케이션 통합), SOA (서비스 지향 아키텍처), BPM (비즈니스 프로세스 관리)와 같은 잘 확립된 접근법을 통해 다뤄질 수 있다 [EBPM]. 이는 우리가 다음 장에서 살펴볼 내용이다.
IoT 데이터를 이해하는 것은 효율적인 분석을 필요로 한다. 이는 우리가 다음에서 볼 것처럼, 빅데이터에만 적용되는 것이 아니다. 분석에는 다양한 유형이 있다. 일부 분석은 단순히 과거 사건을 검토하지만, 좀 더 향상된 분석 유형은 미래의 사건 및 발전을 예측하기 위해 과거 데이터를 활용하려고 시도한다. 기본 분석은 다음을 포함한다.
• 기술적 분석: “무엇이 일어나고 있는가?” (예: 엔진이 작동을 멈추었다)
• 진단적 분석: “왜 일어났는가?” (예: 결함 있는 볼트 때문에)
발전된 미래 지향적 분석은 다음을 포함한다.
• 예측적 분석: “무슨 일이 일어날 것 같은가?” (예: 언제 엔진이 작동을 멈출 것 같은가?)
• 지시적 분석: “이러한 일을 미연에 방지하기 위해 무엇을 해야 하는가?” (예: 고장나기 전에 볼트를 교체한다)
모든 IoT 솔루션이 위의 데이터 유형과 분석 유형을 모두 활용하는 것은 아니다. 사실 데이터 관리 아키텍처 및 선택된 툴이 정말로 필요한 것에 한정되도록 하는 방법을 이해하는 것은 프로젝트 관리자에 매우 중요하다. 다음에서 볼 수 있는 바와 같이, 다른 기술들을 결합하는 좋은 방법이 있기에, 최소 기능 제품 (MVP) 철학으로 시작하는 것은 의미가 있다. 물론, 예를 들어 관계형 대 NoSQL에서 오른쪽 핵심 데이터 관리 기술을 선택하는 것은 신중한 분석에 기초해야 한다.
네 개의 IoT 데이터 관리 시나리오
Ignite | IoT 방법론을 사용하는 IoT 프로젝트 관리자가 데이터 관리를 위한 올바른 아키텍쳐와 기술을 더 쉽게 확인할 수 있도록하기 위해서, 우리는 네 가지 기본 시나리오를 정의했다. 우리는 점차적으로 IoT 데이터 관리 아키텍처와 기술의 다양한 옵션에 대한 논의를 구성하기 위해 이러한 시나리오를 사용할 것이다.
시나리오 A는 비교적 간단하다. 필드에 적당한 수의 자산 (1~2천개의 자산)을 가정하며 각 시간과 자산 당 들어오는 사건의 수는 매우 적다. 분석은 기본적인 보고와 기술적인 분석으로 한정된다. 우리는 이 시나리오를 “기본 M2M”이라고 부른다.
시나리오 B는 필드에 수십만 개의 자산 및 자산에서 들어오는 많은 양의 데이터를 가진 실제 기업 IoT 솔루션을 가정한다. 이 프로젝트의 초기 초점은 자산으로부터의 데이터 스트림을 분석하고 중요한 사건에 “실시간”으로 반응하는 것에 있다 (완전한 실시간이 아닌 예를 들어 1초 이내). 우리는 이 시나리오를 “기업의 IoT 및 CEP”라고 부르며, CEP는 복잡한 사건 처리 (Complex Event Processing)를 의미한다.
시나리오 C는 오랜 기간 동안 대규모로 필드 데이터를 저장하기 위한 요건을 추가하는 시나리오를 토대로 한다. 기본적인 기술적 분석 및 잠재적으로 진단적 분석이 이 데이터에서 수행될 것이다. 시나리오 D는 시나리오 C의 연장선으로, 예측 및 지시적 분석과 같은 더 향상된 분석이 추가된다.
모든 네 가지 시나리오의 요약은 아래 도표에서 찾을 수 있다.

Overview of 4 IoT data management scenarios
시나리오 A: 기본 M2M
시나리오A의 일반적인 어플리케이션은 모바일 산업 기계 집단 등에 대한 원격 장비 모니터링이다. 제한된 수의 상태 업데이트 및 사건은 시간이 지남에 따라 각 기계에 대해 예상된다. 기본적인 보고는 기계 상태 개요, 기계 활용 등을 보여줄 것이다. 아키텍쳐는 보통 비교적 백엔드가 간단할 것이다. 초기의 어려움은 대부분 자산의 통합 및 자산에 필요한 장치 인터페이스를 가지는 것에 초점을 맞출 것이다 (IoT 게이트웨이에 대한 기술 프로파일 논의 참조). 아래 그림은 시나리오 A의 AIA를 보여준다.
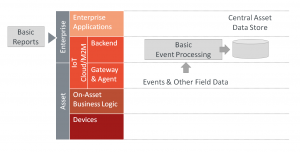
Architecture for data management in basic M2M
기술 선택의 관점에서, 어떤 데이터 저장소가 자산과 필드 데이터를 관리하기 위해 사용되어야 하는지, 그리고 어떤 인터페이스 기술이 원거리 자산을 통합하느데 사용되어야 하는지에 대한 두 가지 핵심 결정이 이루어져야 한다.
데이터 저장소의 경우, RDBMS와 NoSQL를 포함하는 많은 상이한 옵션이 있다. 많은 일반적인 M2M 어플리케이션 플랫폼은 RDBMS 기술을 기반으로 하고 있으며, 이는 대부분의 경우 완벽하게 잘 작동한다. 하나의 장점은 백업 관리에의 보고로부터 관련 도구의 풍부한 생태계를 기반으로 한다는 것이다. 또한, 대부분의 조직은 RDBMS 기반의 솔루션을 구축하고 운영하는 데 필요한 기술을 지닐 것이다.
그러나, 시간이 지남에 따라 시나리오가 확장될 가능성이 있는 경우, 예를 들어 조금 더 복잡한 어플리케이션이 개발되거나 분석 요건이 향후 좀 더 진보된 시계열 분석을 포함할 가능성이 있는 경우, 솔루션 설계자는 대신 NoSQL 데이터베이스를 고려하는 것이 낫다.
두 번째 기술 결정은 자산의 통합과 그것으로부터 스트리밍되는 다른 데이터 및 사건의 관리에 관한 것이다. M2M 또는 IoT 어플리케이션 플랫폼이 사용되는 경우, 이 기능이 내장될 가능성이 높다. 맞춤형 발전의 경우, 여러 옵션이 있다. 아주 기본적인 어플리케이션에서는 어플리케이션 서버 또는 NodeJS와 같은 기본 사건 처리 기술이 사용될 수 있다. 정립된 메시징 및 대안 적으로 또는 추가로 사용될 수 있는 관련 기술의 부족함이 없다. 마지막으로, MQTT와 같은 일부 IoT에 특화된 메시징 솔루션이 등장하기 시작했으며, 이는 그들의 특정 성격 때문에 추가적인 혜택을 제공해야 한다. 아래 그림은 개요를 제공한다.
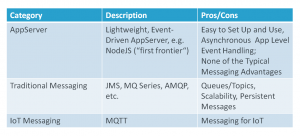
Basic event processing technologies
시나리오 B: 기업 IoT 및 CEP
시나리오 B는 필드에서 훨씬 많은 자산을 다루고 있다고 가정하거나, 자산이 백엔드에 훨씬 많은 양의 데이터를 제공하고 있다고 가정하거나, 둘 모두를 가정한다.
이 시나리오에서 데이터 스트림에의 밀접한 모니터링이 종종 필요하며, 특정 유형의 상황에 신속하게 반응하는 능력 또한 필요하다. 대부분의 경우, 실시간으로 특정 패턴의 데이터 스트림을 분석할 필요가 있으며, 그 예로 온도의 급격한 증가를 들 수 있다.
이러한 경우에 매우 유용할 수 있는 하나의 기술은 복잡 사건 처리 (CEP)이다. CEP는 다수의 데이터 스트림으로부터의 데이터는 비지니스 수준에서 특정 의미를 갖는 패턴을 추론하기 위해 추적되고 분석될 수 있다. 빨간색으로 바뀌는 신호등과 동시에 도로를 건너는 보행자가 그 패턴의 예이다. 따라서, 하나의 흥미로운 CEP 사용 사례는 센서 데이터 융합의 영역에 있다 (IoT 게이트웨이 기술 프로파일 참조). CEP의 전반적인 목적은 관련 사건의 비즈니스 로직을 식별하고, (거의) 실시간으로 그들에 응답 할 수 있게 되는 것이다.
Oracle의 프로젝트 관리 감독자인 Robin Smith는 우리를 위해 다음과 같이 CEP의 기본 사건 패턴을 요약했다.
필터링
• 데이터 스트림은 200F 미만의 온도 등 특정 범위에 대해 필터링된다.
상관 관계 및 집계
• 스크롤링, 지난 3일간 평균 맥박수 등의 시간 기반 창문 지표
패턴 맞추기
• 15분 내에 일어나는 기계 사건 A, B, C 등 감지된 사건 패턴의 알림
지리, 예측 모델링 및 그 외
• 지리적 움직임 패턴의 즉각적 인식, 데이터 마이닝 알고리즘을 사용하는 과거 비지니스 지능형 모델의 어플리케이션
아래 그림은 CEP의 기본 원칙을 보여준다.
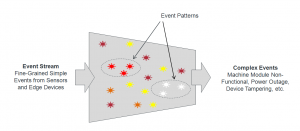 Basic principle of CEP
Basic principle of CEP
사례: 지속적 문의 언어 (CQL)
CEP에서 사건 흐름을 분석하는 잘 정립된 방법의 한가지 좋은 예는 표준 SQL 언어의 확장인 지속적 문의 언어 (CQL)이다. CEP을 지원하기 위해 시각적 모델러를 이용하는 많은 도구를 포함하여 많은 다른 방법이 있다. 우리는 기본 원리를 설명할 수 있도록 우리의 예로 CQL을 사용할 것이다.
Oracle의 프로젝트 관리 감독자인 Robin Smith는 다음과 같이 CQL을 설명한다.
• CQL은 필터링, 분할, 집계, 상관 관계 (스트림에 걸쳐) 그리고 스트리밍 및 관계 데이터에 일치하는 패턴을 조회
• CQL은 스트림의 개념, 관계와 스트림 사이의 매핑을 위한 사업자, 패턴 매칭의 확장을 추가하여 표준 SQL을 확장
• 원도우 사업자 (예를 들어 RANGE 1 MINUTE)는 스트림을 관계로 변환
아래의 간단한 예는 선택된 스트림에 데이터를 전송하는 모든 온도 센서에 대한 마지막 순간의 평균 온도를 계산한다.
SELECT AVG(temperature) AS avgTemp, tempSensorId
FROM temperatureInputStream[RANGE 1 MINUTE]
GROUP BY tempSensorId
CEP 및 IoT
IoT의 맥락에서, CEP는 자산 또는 백엔드, 또는 둘 모두에 배치될 수 있다. 아래 그림은 후자를 보여준다. 자산에 CEP를 배포하는 것은 (경계가 흐려질 수 있기 때문에, 게이트웨이와 자산 상 비지니스 로직 모두를 포함하는 것으로 여기서 보여진다) 많은 사건이 지역적으로 이용되거나 (자산 자율성) 백엔드로 전달 (사건 전달)되기 전에, 미리 필터링되거나 결합 (센서 융합)될 수 있다는 장점을 갖는다. 또한, 상황에 맞는 데이터 (날씨 예보 등)는 의사 결정 과정에 보다 쉽게 추가될 수 있다.
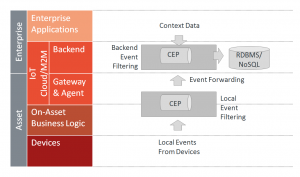
CEP and Enterprise IoT
사례 연구: Emerson
Emerson은 제품을 제조하고 광범위한 산업, 상업 및 소비자 시장에 대한 엔지니어링 서비스를 제공하는 미국의 다국적 기업이다.
The Emerson Trellis™ 플랫폼은 재고 관리, 현장 관리 및 전력 관리를 결합한 데이터 센터 인프라 관리 솔루션이다. 이 솔루션은 저장 장치, 서버, 전원 시스템 및 냉각 장치에 연결하는 로컬 게이트웨이 기기를 사용한다. CEP는 데이터 집계, 필터링, 대규모 환경에서의 실시간 의사 결정을 지원하는 처리를 위한 이 솔루션에서 사용된다. 아래 그림은 솔루션 구조의 개요를 제공한다.
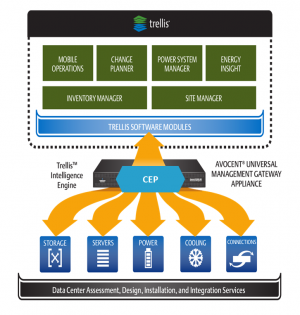
Emerson Trellis Platform (Source: Oracle)
시나리오 C: 빅데이터 및 기본 분석의 추가
시나리오 C는 솔루션이 매우 큰 데이터 규모로 장기 자산 데이터 분석을 수행할 수 있어야 한다고 가정한다. 여기에서, 경계는 종종 명확하지 않다. 많은 CEP 시스템은 매우 큰 데이터 볼륨으로 확대될 수 있을 것이다. 그러나, 다음에서 볼 수 있는 것처럼, 빅 데이터는 볼륨 이상의 것이다.
빅데이터
빅데이터에 대한 많은 서로 다른 정의가 있으며, 보통 지속적으로 진화하는 개념으로 이해해야 한다. 빅데이터는 일반적으로 정보를 이용하기 위한 의도로 저장되어 반 구조화, 구조화 및 비 구조화 된 매우 많은 양의 데이터를 의미한다. 빅데이터를 “빅데이터”라고 간주하도록 하는 특정 숫자가 있는 것은 아니지만, 일반적으로 페타 바이트, 아니면 엑사 바이트의 데이터를 의미한다. 이러한 ERP 및 CRM 등의 전통적인, 대규모 기업 어플리케이션은 보통 테라 바이트 수준에 아른다.
빅데이터의 원동력은 전통적으로 구글, 페이스북 등의 대형 인터넷 기업이었다. 예를 들어, 구글의 엔지니어들은 데이터 및 문의가 수천 개의 서버에 분산될 수 있게 만드는 MapReduce의 초기 개념을 정교화했다. 야후와 같은 다른 회사와 함께, 이 개념은 지금 Cloudera (이 챕터의 시작 부분에서 인터뷰 참조)와 Hortonworks와 같은 스타트업 회사에서 지원하는 Hadoop이라는 오픈 소스 상품으로 구현되었다. 이 분야에서 틀림없는 선도 기업인 구글은 또한 Flume과 MillWheel을 기반으로 한 Cloud Dataflow와 같은 차세대 기술을 도입했다.
사용되는 기술에 관계없이, 빅데이터는 기존 RDBMS/OLAP 시장에 많은 변화를 가져왔다. 주요 변화 중 하나는 빅데이터가 고도로 구조화된 유형에서 완전히 비구조화된 유형까지, 많은 다른 유형의 데이터를 관리하는데 매우 적합해졌다는 점이다.
이 인프라를 기반으로, 예를 들어, 새로운 Data Lake 개념은 기업들에게 생각을 거꾸로 뒤집을 것을 제안한다. 먼저 데이터베이스 구조를 정의하고, 그 다음 이 구조에 맞는 데이터를 채우는 것이 아니라, Data Lake는 단순히 모든 종류의 데이터를 저장하고나서, 필요할 때, 필요한 형식으로 이 데이터를 활용한다. Doug Laney (Gartner)는 많은 사람들이 가장 짧고 일반적인 빅데이터의 정의라고 생각하는 내용에 대한 설명을 처음 제공한 공로가 있다. 그 정의는 3 V로, 양 (volume: 많은 양의 데이터를 처리), 속도 (velocity: 거의 실시간으로 빠른 속도의 데이터 흐름을 처리), 다양성 (variety: 다양한 형태의 데이터를 처리) 이다. 어떤 사람들은 빅데이터 “V”에 변화성 (variability 또는 불일치)과 정확성 (veracity: 데이터 품질)를 추가하기도 한다.
기본 분석
빅데이터의 기본 분석은 일반적으로 기술적, 진단적 분석을 포함한다. 기술적 통계는 그룹화 또는 필터링된 데이터 세트에 적용될 수, 합계, 평균, 백분율, 최소 및 최대값, 간단한 연산을 포함한다.
어떤 사람들은 사업 분석의 80 %가 기술적 분석이며, 특히 소셜 미디어 분석이 그러하다고 주장한다 [LI1]. 예시는 페이지 뷰, 게시물 수, 언급, 팔로워, 평균 응답 시간 등을 포함한다.
많은 IoT 프로젝트의 탐구적 성격 때문에, 많은 프로젝트가 처음에 이러한 기술적 분석 (작동 장치의 MTBF (실패 사이의 평균 시간) 등의 통계 분석과 같은 것들에 대한)에 의존할 것이라 가정할 수 있다. 진단적 분석은 또한 기본 IoT 데이터 분석에 중요한 역할을 할 것이다. 몇몇 작동 장치에 문제가 발생한 경우, 신속하게 그것을 해결하기 위해 가능한 한 빨리 근본 원인을 식별할 수 있는 것이 중요 할 것이다.
문제 상황에의 NoSQL 추가
비구조화된 빅데이터 저장소 외에도, 문서 지향의 NoSQL 데이터베이스 또한 IoT의 맥락에서 중요한 역할을 하기 시작한다. 다음에서 우리는 IoT, NoSQL, 빅데이터의 주요 측면을 MongoDB 의 CEO인 Max Schireson과의 인터뷰를 통해 논의해볼 것이다. MongoDB는 NoSQL 데이터 관리를 위한 오픈 소스 데이터베이스를 선도하고 있다..
Dirk Slama: 무엇이 오늘날의 IoT 현실에서 빅데이터를 만들고, 어떻게 NoSQL가 이에 적합하게 됩니까?\
Max Schireson: 지난 5년 동안, 우리가 지난 30년 동안 본 것보다 더 많은 데이터 관리에 발전이 있었습니다. 범용 컴퓨팅, 오픈 소스 기술 및 클라우드의 성장으로, 데이터를 수집, 저장, 처리, 분석하는 것이 매우 저렴해졌습니다.
이러한 발전은 작동 작업량을 제공하는 NoSQL 데이터베이스와 분석 작업량을 제공하는 Hadoop의 출현을 보았으며, 이는 일반적으로 기존 기술들을 보완합니다.
데이터 저장 및 처리 요건처럼 확장성 벽에 충돌하는 대규모 웹 자산으로부터 등장한 이러한 많은 개념은 관계형 기술의 한계를 빠르게 성장시킵니다. 그들은 또한 그들 데이터의 대부분이 깔끔한 행과 열 형식에 적합하지 않아서, 쉽게 관계형 데이터 모델에서 표을 사용하여 관리할 수 없다는 사실을 발견했습니다. 어플리케이션 요건은 급진적으로 변화했고 정적 관계 스키마는 개발자의 민첩성을 방해했습니다. 이는 IoT에서 설계자와 개발자가 직면하고 있는 문제입니다. 자체 데이터 센터 또는 클라우드에서, 저가의 범용 서버와 로컬 스토리지의 집단에 NoSQL 데이터베이스와 Hadoop 클러스터를 확장할 수 있는 능력은, 설계자로 하여금 수십억 개의 센서에 의해 생성된 데이터 볼륨에 관한 문제를 해결할 수 있게 합니다. MongoDB에 의해 사용되는 문서 모델 등 새로운 데이터 모델은 설계자들로 하여금 사건에서 시계열 데이터, 지리적 좌표, 텍스트, 다형성 2진법 데이터까지 구조화된 데이터뿐만 아니라, 반구조화, 비구조화, 다형성 데이터 또한 저장 및 처리 할 수 있게 합니다.
병렬 프로그래밍의 발전은 계산할 데이터를 이동하여 시간과 비용을 들이기 보다는, 데이터 계산 자체를 이동시켜 복잡한 알고리즘이 클러스터 주위로 분배되도록 하였습니다. 이것은 우리가 이전보다 빠르게 훨씬 더 많은 양의 데이터를 분석 할 수 있음을 의미합니다. 우리가 데이터를 저장, 처리 및 분석하는 방법에서의 이러한 근본적인 변화는 IoT에 데이터 관리를 위한 기반을 제공한다.
Dirk Slama: 최신 데이터베이스는 loT에서 무슨 역할을 합니까? 전통적인 데이터베이스가 여전히 맡고 있는 역할이 있습니까?
Max Schireson: 오늘날의 많은 NoSQL 데이터베이스는 loT어플리케이션의 가동적인 부분을 담당합니다. 센서 데이터는 NoSQL 데이터베이스에 의해 수집되고 저장됩니다. NoSQL 데이터베이스 내에서 이것은 온라인 보고 대시보드에 제공하고 행동을 유발하기 위해서, 종종 어플리케이션 미들웨어 내에 만들어진 사업 규칙을 사용하여 조회되고 평가됩니다.
소매 업계에서의 예시를 살펴보면, 상점 내 신호의 네트워크는 상점 내 고객의 위치를 식별할 수 있으며 그들에게 공지를 전송합니다. 예를 들어, 사용자는 구매 목록을 자신의 스마트폰에 작성하고 이것을 운용 데이터베이스에 저장하는 상점 어플리케이션과 공유할 수 있습니다. 상점에 들어갈 때, 상점 어플리케이션은 고객에게 구매 목록에 있는 상품이 강조되어있는 지도를 보여줍니다. 구매 목록에 있던 상품 군이 진열된 위치에 다가가면, 어플리케이션은 고객에게 이것을 알리고 특정 브랜드를 추천해줍니다. 또다시, 그 추천 목록은 운용 데이터베이스에 저장됩니다. 계산하는 지점에서, 시스템은 RFID를 이용해서 장바구니에 있는 모든 물품을 자동적으로 인식하고 영수증을 만들며, 스마트폰으로 결제를 진행합니다. 계산 과정이 끝나면, 가게의 재고 시스템이 자동으로 갱신됩니다.
이 시나리오에서, NoSQL 데이터베이스는 실시간으로 가게 내 고객의 움직임을 저장하고 제품의 정보와 함께 추천을 제공합니다. 더 많은 전통적인 관련 데이터베이스가 청구서 및 송장 발부 관리를 위해 NoSQL 데이터베이스와 결합하여 사용될 수 있습니다. 그래서, 관련 데이터베이스는 종종 새로운 loT 어플리케이션에 통합된 말미의 기업 시스템에서 ‘기록 시스템’의 역할을 하기도 하며, 여전히 loT 어플리케이션에서 사용되고 있습니다.
Dirk Slama: loT에서 Hadoop이 맡은 역할은 무엇입니까? 전통적인 EDW가 아직 역할을 보유하고 있습니까?
Max Schireson: 이는 예시를 통하여 가장 잘 설명됩니다. 위에서 언급한 소매상 사용을 진행할 때, 고객의 모든 행동은 NoSQL 데이터베이스 내에 저장됩니다. 그리고 나서, 소셜 미디어나 축적 고객 데이터로부터 의견을 구매하는 웹로그의 클릭 스트림같이, 다른 소스와 함께하는 데이터와 결합된 Hadoopd로 로딩됩니다. 이 모든 데이터 요소들은 고객이 다시 상점을 방문했을 때 실시간 추천을 제공하기 위해서, NoSQL 데이터베이스에 다시 로딩될 수 있는 심화된 행동 모델을 만듭니다.
관련된 데이터베이스처럼, EDW는 새로운 데이터 소스를 지원할 규모의 용량이 제한되어 있으며, 데이터 모델이 대답하기에 구체적으로 설계되어있지 않은 탐사적인 질문을 다루는 데에 효과적이지 않습니다. 이들은 EDW를 대체하기보다는 보조하기 위해 배치된 Hadoop에 의해 제기된 문제입니다. Dirk Slama: loT데이터 라이프사이클을 관리하기 위해 이런 최신 데이터베이스와 Hadoop 기업 데이터 허브를 어떻게 통합했습니까?
Max Schireson: loT 설계가 NoSQL데이터베이스나 Hadoop과 통합할 수 있는 데에는 구매 스크립트부터 상품화되고 지원된 연결기까지, 여러 방법이 있습니다. 후자의 예시는 Hadoop에 쓰인 MongoDB 연결기입니다. 이는 Apache Hadoop과 선두적인 산업 유통 모두에 적합합니다. Hadoop을 위한 MongoDB 연결기는 사용자들이 Hadoop플랫폼 및 그 기능과 함께 MongoDB 로부터 실시간 데이터를 통합하도록 해줍니다. 연결기는 Hadoop job(MapReduce, Hive, Pig, Impala 등)이 MongoDB로부터 데이터를 HDFS에 복제하지 않고 바로 읽도록 하여, Hadoop 데이터 소스로써 MongoDB를 제공합니다. 그렇게 함으로써, 시스템 사이의 데이터 TB를 이동할 필요가 없어집니다. Hadoop job은 필터로 질문을 통과하여, 모든 목록을 살펴볼 필요가 없고 프로세싱을 빠르게 만듭니다. 또한 MongDB의 문자와 공간 정보를 포함한 색인 기능을 이용할 수도 있습니다. 연결기는 Hadoop job이 존재하는 서류의 증가한 최근 정보를 포함하여 MongoDB에 되돌아가 기록되는 것을 가능하게 합니다. 추가로, MongoDB는 이것 자체로 Hadoop과 같은 물리적 클러스터에서 운영될 수 있기 때문에, 두 플랫폼 사이에는 아주 긴밀한 통합이 발생합니다.
Dirk Slama: 이런 새로운 loT데이터 설계에서 스트림 프로세싱이 하는 역할이 무엇입니까? 여기서 성립된 CEP 개념이 어떻게 적용된다고 생각하십니까?
Max Schireson: 센서, 기기 혹은 자산으로부터 스트림될 때, 존재하는 CEP뿐만 아니라 Apache Strom와 Apache Spark같은 스트림 프로세싱이 결과에 예민하거나 자동화된 행동을 유발하면서 loT데이터에 충돌할 수 있습니다. CEP는 일반적으로 패턴을 찾고 사업 규칙을 적용시키기 위해 데이터를 다수의 소스와 연결시키는, 잘 입증되고 발달된 기술입니다. 이 데이터와 규칙들은 운용 데이터베이스에 저장됩니다. Spark나 Storm같은 스트림 프로세싱은 더욱 최근 의 발달이며, 일반적으로 하나의 데이터 스트림을 작동시키고, 또 일반적으로 데이터, 규칙, 행동을 작동시킵니다. 모두 사용 사례나 개발자 기술에 따라서 loT에서 역할을 갖고 있습니다.
Dirk Slama: 통찰력을 얻거나 새로운 프로세스를 자동화시키기 위해 어떻게 loT데이터를 분석하십니까? Hadoop, 데이터베이스, 센서 데이터 스트림에서 이루어집니까?
Max Schireson: 이는 세가지 모두에서 이루어질 수 있습니다. 분석은 정보 루트를 가공하는 원 데이터를 사용한 데이터베이스에서 조정되는 실시간 프로세스나 항공(스트림)내의 데이터에 충돌할 수 있습니다. 또, 다양한 소스로부터 받아들여진 데이터를 저장하는 Hadoop에서도 충돌할 수 있습니다.
그래서 이전의 소매업 예시로 돌아가보면, 스트림 분석은 고객이 상점에서 나가는 것을 감지합니다. 데이터베이스는 고객의 상세 정보를 검색하고 이를 선호도나 상품 판촉에 맞춥니다. 고객의 활동과 구매는 추적되고, 데이터베이스에 저장된 후 이 새로운 데이터가 분석 모델을 조정하는데 사용되는 Hadoop에 로딩됩니다. 이 데이터는 다시 데이터베이스로 로딩되고, 고객이 재방문 했을 때, 더 적절한 제안이 제공됩니다.
빅 데이터 인프라 구축
시나리오 C는 자산 데이터 스트림의 실시간 분석 대신, 이런 ‘수명이 짧은’ 데이터에 장기 패턴 분석을 수행하기 위해 데이터를 더 오래 유지하는 것을 원한다고 가정한다. 이 시나리오는 스트림 프로세싱과 결합된 빅 데이터 기반을 구축하는 것에 중점을 두고, 이 데이터를 분석하기 위해 사용될 수 있는 몇 가지 기본적인 알고리즘을 소개한다.
Pentaho의 최고 상품 책임자인 Christopher Dziekan은 설명한다. “모든 사람들은 종종 빅데이터의 세가지 V인 양, 다양성, 속도 (Volume, Variety, Velocity)를 지적하며 데이터 (혹은 빅 데이터)를 거대한 가치와 자산으로 바꾸는 것을 염려합니다. 이 V들은 구조적으로 변화를 추진합니다. 그러나, 기업들이 그들의 빅 데이터 기반을 제작하면서 더 많은 V들이 시행됩니다. 빅 데이터 기반은 처음 세 V에 필요한 반응이지만 정확성 (Veracity)과 가치 (Value) 또한 동등하게 고려되어야 합니다.” 빅 데이터의 모든 V를 포함하기 위해서는 큰 범위의 상품 배치를 가능하게 하는 구조와 방법론을 살펴봐야 한다.
정보를 전략적인 장점으로 바꾸려면, 사업 분석과 데이터 통합을 결합시키는 빅 데이터 ‘조직화’ 플랫폼이 필요하다. loT 기기로부터 발생된 데이터를 관련된 데이터와 새로운 데이터 소스 모두와 조합하면서 발전된 분석 기술이 적용된다. 영업부문과 운영상의 결정을 지지하면서 영향을 주려는 순간에 보편적으로 가능하도록, 플랫폼은 존재하는 IT 기반에 적합해야 하며 사업 어플리케이션에 연결되어야만 한다. loT 시스템과 적용하여 다른 사용자 집단의 분석적인 필요를 조사하면서, 우리는 어떠한 도구나 저장소도 완벽하게 모든 사용자의 필요에 맞지 않다는 것을 볼 수 있다. 일부는 전통적인 데이터 시장과 데이터 창고를 필요로 한다. 어떤 이들은 정제 공장에 덧붙여, 즉석 데이터 기반에 요구되는 ‘데이터 강’ 저장소를 필요로 할지도 모른다. 또 다른 이들은 기기 상태를 분석하고, 스트리밍 문의를 실행하고, 공지를 알리기를 원한다. 여전히 어떤 이들은 즉석 데이터 변형과 그들의 데이터 과학자들을 위한 특별한 도구의 배열을 필요로 한다.
이러한 다양한 요건을 감안할 때, 우리는 어떻게 모든 요구를 충족시키는 데이터 아키텍처를 구축할 수 있을까? 우선 우리는 전체 아키텍처를 관리할 수 있게 하는 도구의 집합 또는 플랫폼이 필요하다.
Lambda 아키텍쳐
하나의 엔진에 일부 이러한 요소를 결합하는 한 가지 방법은 Nathan Marz에 의해 도입된 Lambda 아키텍처라고 알려져 있다. Lambda 아키텍처는 기록 데이터를 모두 저장하는 “배치 층”과 실시간으로 데이터를 처리하는 “속도 층” 및 다른 두 가지 층을 모두가 조회되도록 허용하는 “서빙 층”으로 구성되어 있다.
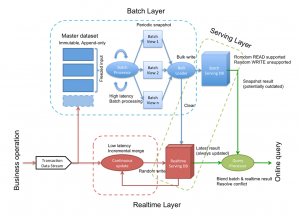
Lambda Architecture (Source: Ricky Ho [RH1])
우리는 모든 층이 잘 수행되기를 원하기 때문에, 이름 “배치 층”은 Pentaho의 James Dixon에 의해 만들어진 용어 “데이터 호수”로 여겨지는 것이 낫다 [FO1]. 그리고 속도 층은 “실시간 층”으로 생각되어야 한다.
Lambda 아키텍처는 IoT 시스템에 대한 데이터 아키텍쳐의 몇 가지 문제를 해결하지만, 명시 적으로 모든 기기의 상태를 저장하거나 조회할 수 있는 방법을 제공하지 않는다.
IoT 데이터 아키텍쳐
Lambda 아키텍처는 IoT 시스템을 만들기 위한 지도 원칙으로 사용될 수 있다.
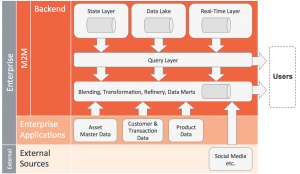 IoT and big data – integration perspective (based on input from Pentaho)
IoT and big data – integration perspective (based on input from Pentaho)
다이어그램에서 당신은 IoT 데이터 아키텍처가 실시간 층, 데이터 호수/기록 층, Lambda 아키텍처의 문의 층을 포함하고 있는 것을 확인할 수 있다. 또한 상태 층 및 융합/변환/정제/ 데이터 마트 층을 보유하고 있다.
Pentaho의 James Dixon은 그의 “상태의 조합” 개념에서 상태 층과 데이터 호수 사이의 중요성을 정교화했다. 이 주제에 대한 블로그 포스트에서 Dixon은 어플리케이션의 데이터의 주요/일반적인 영역뿐만 아니라, 초기 상태와 모든 속성의 변화를 포착할 것을 권장한다. 그는 모든 증가하는 변화 및 사건을 저장하여, 상태 로그의 각 자체 데이터 호수와 함께 여러 어플리케이션에 이 방법을 적용할 것을 주장한다. 이는 “상태의 조합”과 시간에 걸쳐 기업에서 (잠재적으로) 모든 비지니스 어플리케이션의 모든 영역의 상태를 포착하는 결과를 낳는다.
이 접근법은 많은 상황에 적용될 수 있다. 예를 들어, 전자 상거래 업체는 과거에 어떤 특정 순간 동안, 몇 개의 쇼핑 카트가 열려 있는가, 그 안에는 무엇이 있었는가, 어떤 거래가 진행 중인가, 어떤 항목이 박스 포장되거나 이동 중인가, 무엇이 반품되었는가, 누가 일하고 있는가, 얼마나 많은 고객 센터 전화가 대기 중이고 진행 중인 것은 몇 개인가를 알아낼 수 있었을 것이다. 본질적으로, 이 방법은 추세 분석 및 규정 준수 등의 프로세스를 지원한다.
지금까지, Lambda 아키텍처 제품 또는 그것으로의 IoT 확장을 제공하는 어플리케이션 또는 도구가 만들어지지 않았다. 이는 IoT 구현 팀이 IoT 시스템의 능력, 효율성 및 효과성을 극대화하기 위해, 설계 시 고려해야 하는 것이다.
시나리오 D: 향상된 분석의 추가
빅데이터 관리 및 IoT를 위한 인프라가 구축되고 나면, 다음 단계는 데이터가 분석되는 정교함의 수준을 증가시키는 것이다. 이는 예측적 진단적 분석을 포함한다. 진단적 분석이 최적화된 결과를 달성하기 위해 행동을 인도하려 시도하는 반면, 예측적 분석은 미래의 사건 및 발전에 대해 예측하기 위해 기록 데이터를 사용한다.
많은 사람들이 실제로 IoT에서 이러한 매우 중요 시나리오를 참조한다. 특히, 산업 IoT 시나리오는 크게 예측적 요지 보수 등의 사용 사례로부터 이익을 얻는다.
이러한 사용 사례들의 복잡성 때문에, 많은 기업이 필요한 사업과 이러한 사용 사례를 지원하는데 필요한 기술 자문, 데이터 분석 스킬을 결합하는 데이터 과학자처럼, 새로운 직업 역할을 찾고 있다.
예측적 분석은 모델링, 기계 학습 및 데이터 마이닝 등의 여러 상이한 기술을 포함한다.
기계 학습
Tapio Torikka 박사는 Bosch Rexroth의 상태 모니터링 프로덕트 매니저이다. 다음에서 그는 [ML1]과 [ML2]를 기반으로 하는 예측적 분석의 중요 요소인 기계 학습에 대한 설명을 제공한다.
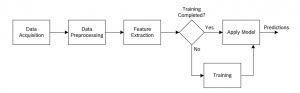
기계 학습은 알고리즘이 예측을 위해 입력 데이터에 기초한 모델을 구축하는 인공 지능의 분야이다. 명쾌함 없이 프로그램된 지침은 영역 지식이 없거나 거의 없는 경우 문제가 해결될 수 있도록 하는 모델을 만드는 데 사용된다. 아래 그림은 기계 학습 알고리즘을 훈련하고 적용하는 과정을 도시한다. 데이터가 선택된 소스로부터 취득된 후, 예를 들어 그 데이터를 확장하고 누락 값을 입력함으로써, 데이터를 사전 처리해야 한다. 사전 처리 후, 특징 추출 단계는 후속 훈련 단계를 향상시키기 위해 데이터로부터 의미 있는 정보를 추출한다. 훈련 단계 동안 훈련 알고리즘은 자체를 향상시키기 위해 기계 학습 모델의 내부 파라미터를 조정하는데 사용된다. 원하는 정확성 또는 소정 트레이닝 시간에 도달하면, 모델을 저장되고 나중에 미지 데이터로 예측을 위해 사용될 수 있다.
Machine learning (Source: Bosch Rexroth)
학습 유형은 다음과 같다.
• 지도 학습
o 분류된 훈련 데이터가 분류 모델을 구축하는데 사용된다.
o 예시 어플리케이션: “보통”과 “스팸” 사이의 이메일 분류
• 자율 학습
o 데이터 구조가 분류 없이 학습된다.
o 예시 어플리케이션: 신용 카드 사기 탐지
• 준 지도 학습
o 적은 양의 분류된 데이터, 많은 양의 분류되지 않은 데이터
o 예시 어플리케이션: 이미지 인식. 적은 양의 수동으로 분류된 인터넷에서 이용 가능한 이미지, 많은 양의 분류되지 않은 인터넷에서 이용 가능한 이미지
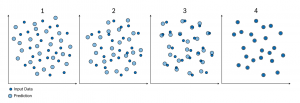
분류된 예시 데이터 (제시된 입력 데이터에 대해 바라는 산출물)가 이용 가능할 때, 지도 학습은 선호된다. 분류된 데이터가 거의 없거나 사용할 수 없는 경우, 준 지도 학습 또는 자율 학습이 사용될 수 있다. 간단한 자율 훈련 과정은 아래 그림에 도시되어 있다. 알고리즘은 모델 (하늘색 원)에 의해 주어진 예측이 입력 데이터 (진한 파란색 원)와 일치하는 방식으로 그것의 파라미터 조정을 시도한다. 이러한 유형의 모델은 비정상행위 탐지에 사용될 수 있다. 즉 모델은 입력 데이터의 주어진 부분이 훈련 데이터와 동일한 구조를 나타낼지 예측할 것이다.
 Example for unsupervised training process (Source: Bosch Rexroth)
Example for unsupervised training process (Source: Bosch Rexroth)
두 개의 구별되는 유형의 모형은 기계 학습 과정의 훈련 단계 동안 구축될 수 있다.
• 분류: 기계 학습모델 (예측)의 산출물은 이산적이다
• 회귀: 모델의 산출물은 연속적이다
분류기는 훈련 데이터에 제시된 것처럼 n 개의 카테고리로 데이터를 분리한다. 예를 들어, 이메일을 분류하도록 구축된 분류기는 내용에 따라 정상 또는 스팸 메일로 분류한다. 회귀 모형은 연속 신호, 예를 들면 정의된 목표 신호의 미래 값을 예측하는데 사용될 수 있다.
사례 연구: 산업 어플리케이션 상태 모니터링을 위한 기계 학습
다음 사례 연구는 Bosch Rexroth의 상태 모니터링 프로덕트 매니저인 Tapio Torikka박사에 의해 제공된다.
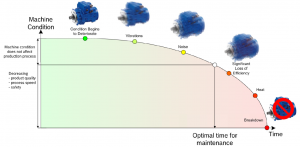
상태 모니터링에서 기계의 상태가 수집된 센서 데이터에 기초하여 평가된다. 이는 사업자가 자산의 유지 보수 작업을 최적화하고 예기치 못한 중단의 위험을 줄일 수 있게 한다 (아래 그림 참조). 일반적으로 이러한 시스템은 연속적으로 작동된다 (이는 온라인 상태 모니터링으로 알려져 있다).
 Machine condition monitoring (Source: Bosch Rexroth)
Machine condition monitoring (Source: Bosch Rexroth)
산업 환경에서 기계는 매우 복잡하며, 그래서 자신의 건강 상태를 평가하는 것은 매우 어려울 수 있다. 많은 기계는 특정 어플리케이션을 위해 특별히 만들어지며, 따라서 고유한 동작을 나타낸다. 또한, 온도 변화 등, 소음, 진동 등 환경의 영향은 센서 신호에 영향을 미칠 수 있다. 설상가상으로, 산업 기계는 기계의 매우 동적인 생산 사이클의 결과로서 부분적으로 고주파 측정을 필요로 하기 때문에, 매우 많은 양의 데이터를 생산하는 경향이 있다. 이러한 특성은 수동으로 개별 센서 신호 또는 간단한 규칙을 검사하여 기계의 유지 보수 상태를 모니터링하는 것이 거의 불가능하다 것을 의미한다.
대용량의 데이터를 저장하는 것은 더 이상 문제가 아니며 사용 가능한 빅데이터 솔루션을 구현함으로써 해결될 수 있다. 훈련 데이터만을 기반으로 모델을 생성하는 기계 학습 알고리즘의 능력은 이러한 데이터를 합리화하는 데 더 큰 문제를 가져온다. 데이터 과학자는 데이터 전처리 및 학습 알고리즘을 위한 분석 파이프라인을 만들 필요가 있다. 또한, 그들은 영역 전문가와 함께 학습 목표를 정의하고 그 결과에 기초하여 작업 제안을 결정하는 책임이 있다. 기계 학습 알고리즘은 일반적으로 많은 연산력을 필요로 하므로 빠른 컴퓨터로의 접속은 중요하다.
비정상행위 탐지는 데이터 소스에서 비정상적인 행동을 검출하는 일반적인 방법이다. 산업적 맥락에서, 이 방법은 결함이 있는 상태를 나타내는 정상 기계 작동으로부터의 편차를 감지하는데 사용될 수 있다. 비정상행위 탐지는 단지 하나의 기준 상태 (예를 들어, 정상 동작)로부터의 훈련 데이터를 필요로 한다. 실제 예에서, 광산 경영자는 광산에서 광석을 전송하는 데 사용되는 컨베이어 벨트의 Rexroth 구동 시스템의 상태를 모니터링하는 데 관심이 있었다. 이것은 경영자에게 중요한 자산이며, 중단 시간은 수익의 감소로 직결되므로, 항상 작동 중이어야 한다. 센서는 컨베이어 벨트 구동 장치에서 데이터를 수집하기 위해 설치되었다. 원격 빅데이터 시스템은 시스템으로부터 데이터를 저장하는 데 사용되고, 기계 학습 알고리즘은 기계의 일반적인 상태 (예측적 분석의 예)를 나타내는 지표를 생성하는데 사용되었다. 어떠한 고장 데이터도 시스템에서 이용할 수 없었고, 따라서 비정상행위 탐지 알고리즘은 정상적인 동작으로부터의 편차를 나타내기 위해 사용되었다.
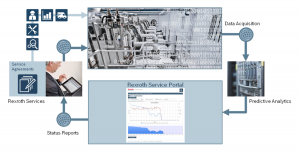
System architecture (Source: Bosch Rexroth)
웹 포털은 데이터를 보고 시스템을 모니터링하기 위해 사용되었다. 아래 스크린샷은 포털의 시각화 화면에서 가져온 것이다.
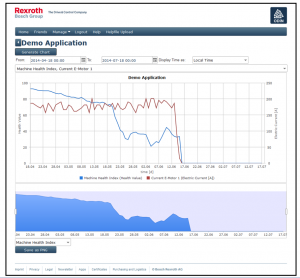 Example screenshot (Source: Bosch Rexroth)
Example screenshot (Source: Bosch Rexroth)
전기 모터 고장이 구동 장치에서 발생했다. 상기 이미지는 시간의 경과에 따른 비정상행위 탐지 알고리즘 (파란색)과 전기 모터 전류 (적색)의 결과를 보여준다. 전동 모터의 전류가 갑자기 추세에 큰 변화 없이 동작의 몇 달 후에 제로로 떨어진다. 다른 센서 신호들의 수동 분석은 시스템의 어떠한 고장도 나타내지 않았다. 이미지에서 알 수 있는 바와 같이, 청색 곡선 (비정상행위 탐지 알고리즘의 결과)은 모터가 고장나기 전에 정상 수준 (90-100)에서 상당히 벗어나기 시작한다. 이것은 복잡한 데이터 이해하기 위한 기계 학습 알고리즘의 능력을 나타낸다. 수동 데이터를 분석은 대용량의 데이터와 동시에 이용 가능한 모든 센서 신호를 평가하는 것의 복잡성 때문에 불가능한 작업이었을 것이다.
사례 연구: 항공 엔진 분석
다음의 사례연구는 Intel 사의 그래프 분석 부서에서 수석 선임 엔지니어이며 총괄 매니저인 Ted Willke로부터 제공되었다.
큰 데이터 시스템은 로그와 기계 원천 데이터로부터의 통계자료를 계산하기 위해 종종 사용된다. 이 정보는 엔지니어들과 데이터 과학자들이 작동을 감시하고, 실패를 확인하고, 수행 결과를 좋게 만들며, 미래 설계를 향상시키기 위해서 사용될 수 있다. 항공 엔진은 세계에서 가장 복잡한 기계 중 하나이다. 항공 엔진들은 물리학의 많은 관점을 하나로 합치고 극대화된 범위의 조건에서 운영해야만 한다 [LYYJL]. 항공 엔진들은 안전에 대한 걱정과 비행에 대한 방해가 발생하기 전, 진단법이 미리 잠재적 실패를 발견하기 위해 자주 관찰된다.
전통적으로 엔진 상태에 대한 짤막한 묘사와 고장 코드는 비행 중에 얻어져 일지에 기록하고 감시를 위해 지상 기지로 보내진다. 그러나 데이터 전송과 큰 데이터 기술을 사용할 수 있는 규모를 모두 소화할 수 있는 IoT 시스템의 이용 가능성과 함께, 엔진 데이터는 오프-보드에서 넓은 차량 지상 기지로 전송될 수 있으며, 지속적으로 관찰될 수 있고, 깊은 통찰력으로 분석될 수 있다 [DSAR]. 같은 데이터의 전송은 지속적으로 같은 비행 조건 하 (고도, 속력, 기온, 운행 시간 등)의 같은 엔진에 의해 수집될 수 있다. 간단한 통계 자료는 엔진이 예상한 바대로 작동했는지 (설계 설명서와 비교하여) 알아내기 위해 이러한 시간의 연속에 기반을 둔 체 계산될 수 있다. 또한 터빈의 압력, 출구 공기 온도, 연료의 흐름 수준 등의 항목에 문제가 있는 것과 같은, 비정상적인 조건을 발견하는 데에도 간단한 통계 자료는 계산될 수 있다.
Category C 시스템은 변칙과 실패를 발견하는 것은 가능하지만, 결함을 따로 분리하고 높은 신뢰도와 정확성으로 결함 원인을 밝혀내는 것은 가능하지 않을 수 있다 [LYYJL]. 게다가 Category C 시스템은 더욱 분명한 변칙과 지속적인 심각한 결함으로 이어질 수 있는 약한 신호 (미세한 변칙)을 발견하는 것도 불가능할 수 있다. 이것이 기계 학습이 도입된 배경이다 (Category D 시스템). 기계 학습은 연구 (이 사례에서는 항공 엔진)에 기반을 둔 시스템 모델을 창조해 낼 수 있다. 그리고 나서 기계 학습은 시스템 행동을 예측하기 위한 모델을 사용할 수 있다. 기계 학습은 데이터 중심 접근 방법이다. 모델의 원형 (유전적 형태)은 선택돼 예측 정확성을 높이기 위해 “훈련된다”. 모델에 의해 패턴은 학습될 수 있기 때문에, 흔한 훈련 과정은 투입물 (무엇을 예측의 기반으로 둘지)과 알려진 산출물 (무엇이 예측이 되었는지)의 쌍을 공급하는 것을 포함한다. 패턴이 학습된 후에는 정확한 예측이 가능하다. 엔진 진단법의 경우에는, 투입물은 엔진의 특징들을 가동하며 예측은 몇몇의 엔진 결함 코드 중의 하나일 수도 있다 (“정상적인” 한가지 코드).
한 가지 연구에서 [LYYJL], 49,900 비행 가치의 데이터는 8가지 엔진 측정으로부터의 1에서 9까지 엔진 결함 조건을 예측하기 위한 기계 학습의 능력의 결정하는 데에 도움이 되도록 분석됐다. 그 기술은 특정한 결함 코드를 유발하는 결함과 초기 결함의 존재를 발견하는 것이 가능한 것으로 보였다.
결론
이 사례 연구에서 살펴본 바와 같이 IoT에서의 데이터 관리에 관해서 매우 다양한 수준의 성숙도가 존재함을 알 수 있다. 우리가 강조한 4가지의 시나리오들은 상품 매니저가 어떤 컴퓨터 시스템의 구성과 기술 해결방안이 그들의 특별한 요구에 부합하는지 결정하는 데에 도움을 줄 것이다. 다음 장에서 우리는 첫째로 산업 어플리케이션에 대한 관점에서부터 기술적인 관점에까지 결론을 제공할 것이다.
산업 4.0 관점
Tobias Conz 씨는 Bosch Software Innovations의 산업 팀의 프로젝트 매니저이다. 그는 고급 IT 개념과 오늘날의 혹독한 IT 제조 환경의 교차점에서 일하고 있다. 그는 다음과 같이 그의 경험을 묘사하고 있다: “제조업과 산업 4.0 분야에서의 데이터 관리는 특히 어렵습니다. 그 이유는 많은 제조업자들이 현재의 환경하에서는 변화가 쉽게 일어나지 않아 투자 주기를 10-15년으로 보기 때문입니다. 한가지 긍정적인 사실은 사실 많은 기계들이 이미 기계 조작을 위해 필요한 방대한 양의 데이터를 모으고 있다는 것입니다. 그러나 산업 4.0전에는 이러한 데이터가 바깥세상에서 실제로 사용 가능하도록 만들 수 있는 요건이 거의 없었습니다. 이것은 우리가 여러 다른 종류들로 이뤄진 인터페이스, 데이터 종류와 프로토콜, 다양한 소프트웨어 버전 등과 같은 일상의 문제를 다뤄야만 하는 매우 기본적인 데이터 통합 시나리오를 바라보고 있다는 것을 의미합니다.
대부분의 기계 데이터가 더 높은 수준으로 통합되지 않았었기 때문에, 통합에 대해 훨씬 이전부터 다뤄왔던 은행과 보험 회사들과는 다르게 우리는 이 공간 속에서 훨씬 높은 수준의 이질성을 찾고 있습니다. 데이터 마이닝, 스트리밍 처리 과정과 같이 새로운 데이터 관리 개념은 물론 제조업과 산업 4.0이라는 맥락에서 매우 흥미로워 보입니다. 이 공간의 특수성에 의해, 우리는 이중의 전략을 추천합니다: 개인 기계 데이터는 어디서든 적용되어 사용될 수 있는 데이터 마이닝 측면에서는 귀중한 발굴 물이라고 할 수 있습니다. 하지만 이러한 목적을 위한 모든 기계의 통합은 거의 불가능합니다. 이것이 우리가 복수의 기계들의 처리 한도를 동시에 유효하게 만들 수 있는 근 실시간 스트리밍 처리 과정을 개발하고 있는 이유입니다. 우리는 이를 한 기계 종류마다 한 번에 하고 있습니다. 이는 어떤 기계 종류가 가장 잘 작동하는지 살펴보기 위함입니다. 가장 큰 어려운 점은 우리가 통합을 위한 시간과 비용 효율 방안을 찾아내야 한다는 것입니다.”
일반적인 추천
MongoDB의 CEO로써 Max Schireson 씨는 떠오르는 IoT 공간에서뿐만 아니라 NoSQL와 일반적인 큰 데이터 기술의 전개에서도 큰 통찰력을 얻을 수 있었다. 아래의 인터뷰에서 그는 프로젝트 매니저를 위한 몇몇 소중한 추천을 제시하고 있다.
Dirk Slama: 무엇이 큰 데이터와 loT 와 관련되어 가장 큰 위험 요소라고 할 수 있습니까? 또한 어떻게 회사들이 이러한 위험요소를 제한하고 회피할 수 있습니까?
Max Schireson: loT와 큰 데이터는 현재 매우 큰 이슈가 되는 주제입니다. 따라서 프로젝트의 첫 번째로 사업 목표에 대해 생각하는 것보다 기술에 직접 뛰어드는 것이 더 쉬울 수 있습니다. 하지만 기술보다 훨씬 중요한 것은 여러분들이 사업이 무엇을 얻으려고 노력하는지 생각하며 이해관계자를 하나로 묶을 필요가 있다는 것입니다. 사업 부문, 당신의 고객들, 당신의 협력자들, 그리고 유용한 기술을 인도하기 위해 일 할 IT 팀들과 같은 이해관계자들 말입니다. 심지어 경쟁자들도 상호 연결성과 통합이라는 측면에서 보면 loT 환경 시스템에서의 중요한 요소가 될 수 있습니다. 여러분들은 loT 그 자체에 대해 언급하면서 이해관계자 특히 고객들을 찾아가서는 안될 것입니다. 여러분들은 loT가 인도할 수 있는 장점들에 대한 대화들의 큰 틀을 짜 볼 필요가 있을 것입니다.
프로젝트가 조직 내의 대부분 고위급에 대한 전략적인 지원 방안을 가지고 있는 것은 중요합니다. 또한 선구자들의 성공과 실패로부터 교훈을 얻기 위해 시간도 가져야 합니다. 탐험적인 자세를 가지는 것이 중요합니다. 미래 사업 모델이 어떤 형태를 띨지 예측할 수 있는 사람이 거의 없는 것처럼 인터넷의 초기 시대에 가장 성공적인 사업 모델이 어떤 현태를 예측한 사람이 거의 없었다는 사실을 기억하세요.
당신은 기술 향상이 필요할 것입니다. 현재의 직원을 데리고 그들을 훈련시키는 방안이든 회사 밖의 제삼자의 전문 영향력을 이용하든 어떤 방안으로든 말입니다. 우리는 정의된 사용 사례를 가지고 있고 장치와 데이터의 부분집합을 위해 사용되는 시범 프로젝트를 시작할 것을 추천합니다. 평가하고, 최대한으로 활용하고, 다시 평가하고. 만약 프로젝트가 증명된 개념과 훈련된 직원들과 함께 성공한다면 더욱 야망을 가지셔도 될 것입니다.
Dirk Slama: 누가 loT로부터 가장 혜택을 받을 수 있을까요? 혹은 누가 가장 손해를 볼 수 있을까요?
Max Schireson: 몇몇 사람들은 때때로 단순히 “어떤 것”의 발명자가 혜택을 볼 것이라고 생각합니다. 이것은 완전히 잘못된 생각이죠. 고객들의 행동을 감시해서 보험료를 최대한으로 할 수 있는 보험 회사나 식품의 생산에서부터 소비에 이르는 식품 공급 사슬을 최대한으로 활용할 수 있는 소매업자들을 생각해보세요. 경제학자들은 75%의 회사들이 회사의 고위급에 현재 loT를 도입할 계획을 세우고 있다고 추정하고 있습니다 [Ref2]. loT와 새로운 사업 모델을 만들 수 있는 데이터/통찰력을 사용하는 회사들과 이를 이용해 그들의 고객들에게 더 다가설 수 있는 회사들이 가장 많은 것을 얻어 갈 것입니다. 현실을 외면하는 기업들은 결국 도태되고 말 것입니다.
Dirk Slama: 큰 데이터와 loT의 적용을 위해 자신들의 전략을 개발하고 있는 독자들에게 한 말씀해주신다면
Max Schireson: 무엇보다 위에서 언급했던 토론 부분에 대해서 다시 말씀드리고 싶습니다. 팀이 그들이 사용하려고 계획한 기술들을 골랐다면 일반적인 최선의 방안들이 있을 것입니다. 그것들은 아래와 같습니다. 기술을 이해하기 위한 시간 (훈련, 독해, 그리고 회의)을 늘려주세요. 새로운 프로젝트의 개발을 돕기 위해 판매회사들과 서비스 공급자들로부터 자원을 사로잡으세요. 발전이 진행됨에 따라, 테크 토크, 해카톤, 프로젝트 위키 등과 함께 최선의 방안과 진행 상황을 공유하세요. 그리고 나서 복수의 프로젝트가 진행 중일 때 최선의 방안이 일상화되도록 CoE를 만들고 확장하세요. 이 공간에는 매우 많은 혁신이 진행 중이고 매우 많은 기술 선택이 존재하기 때문에 여러분은 여러분의 마음을 열 필요가 있습니다. 단지 당신의 ERP 플랫폼을 15년간 성공적으로 운영했기 때문에 데이터 관리 플랫폼을 선택하는 것은 좋은 생각이 아닙니다!
II. IoT와 프로세스 관리
loT 솔루션에 대해 이야기할 때 프로세스 관리는 아마 첫 번째로 언급되는 솔루션은 아닐 수도 있다. 이것은 많은 loT 프로젝트가 처음에는 자산을 얻고 연결된 장치들을 얻는데 어려움을 겪고 그리고 나서 백엔드에 기본적인 서비스들을 구축하기 때문일 것이다. 또한 이번 장에서 의논된 바와 같이 많은 프로젝트들은 국내로 들어오는 사건 흐름을 분석하고 관리하는데 혹은 기본적인 분석을 형성하는데 초점을 맞출 것이다. 하지만 우선 초기의 loT 해결 기능이 갖춰지고 연결 장치와 유입되는 데이터 측면에서 시스템이 규모를 확장한다면, 프로세스의 효율성은 결국 아주 중요한 주제가 될 것이다. loT 솔루션에 관해, 장치들과 자산으로부터 초래된 개인적인 사건들, 복합적이고 간접적으로 연관된 사건 (이전 장의 Complex Event Processing 참고)들을 가리키는 더욱 진보된 분석에 의한 결과에 의해 많은 사업 프로세스는 촉진될 것이다.
예를 들어, 예측 보전에 대해 생각해보자. 논의된 바와 같이 Rexroth 사례 연구에서 정교한 기계 학습 알고리즘은 기계 고장이 임박한 사실을 나타내는 상황을 구별할 수 있도록 데이터 센서를 적용할 수 있다. 당신은 말 그대로 센서 네트워크 전문가와 데이터 과학자들이 이러한 유발점을 어떻게 확인할 수 있는지 몇 주간 머리를 맞대고 고민하는지 확인할 수 있을 것이다. 그러나 다음은 무엇일까? 유압식의 요소인 액체에서의 문제로 인해 ACME 광산의 컨베이어 벨트에서 87.25%의 확률로 다음 주의 월요일부터 수요일까지 고장이 발생할 것이라는 정보로 당신은 무엇을 할 수 있는가? 그리고 이러한 정보의 형태가 당신의 기계요소들을 사용하는 수만의 고객들에게 한 주에 수백 번 들어간다면 당신은 무엇을 할 것인가? 이것이 사업 프로세스 관리 (BPM)가 도입된 정확한 배경이며 이는 이러한 요구 사항들이 효과적으로 진행되며 현장 서비스가 가능할 뿐 아니라 활용될 수 있도록 보장하는데 도움을 준다고 할 수 있다.
또 다른 예를 한번 들어보자. eCall 서비스는 우리가 이미 많이 다뤄본 부분이다. 그렇다. 처음 프로젝트가 초점을 맞춘 부분은 정확하게 잠재적인 고장 상황을 발견하고 또한 이런 정보를 처리할 수 있도록 콜 센터에 보내는 것이었다. 그리고 이것은 적어도 콜 센터 매니저의 관점에서는 정확히 BPM이 시작한 부분이다. 그들은 두 가지에 초점을 맞추었다: 첫째로 적절한 프로세스 실행. 이것은 조난 요청을 분류화하고 적합한 언어 기술과 함께 이를 콜 센터에 전송하는 것을 의미한다. 두 번째로 콜 센터 활용. 오늘날 대부분의 콜 센터는 다양한 서비스를 지원한다. 효율적인 콜-전송 프로세스는 비단 SLAs에 대한 보장뿐만 아니라 수익성을 보장하기 위해서도 매우 중요해졌다.
예를 들어, 수십만의 네트워크 요소와 수백만의 고객들을 기반에 둔 큰 커뮤니케이션 네트워크를 설립하고 운영하고 있는 거대한 통신회사를 생각해보자. 통신회사를 운영하기 위한 TM Forum의 청사진인 eTom은 네트워크 관리에서부터 판매, 생산 활성화 그리고 고객 서비스 요청과 같은 고객 관련 프로세스까지 수백 가지의 비판적인 사업 프로세스를 구분할 것이다. 결국 loT는 그리 달라지지 않을 것이다. 따라서 BPM과 loT에 관해 우리 자신에게 질문해야 되는 흥미로운 질문들은 다음과 같다.
• 프로세스 자동화 관점에서 첫째로 다루어져야 할 loT 솔루션 상의 가장 비판적 프로세스를 우리는 어떻게 구분할 수 있을까?
• 자동화는 얼마에 가능해질 것인가(혹은 바람직할 것인가)?
• 언제 프로세스 자동화를 위해 BPM 툴을 사용해야 하는가? 또한 언제 하드 코드 사업 논리와 같은 다른 접근법들을 사용해야 하는가?
• 무엇이 이러한 프로세스의 본질인가? 예를 들어 조직화된 것, 조직화되지 않은 것 등
• 장치에 대한 소프트웨어 프로비져닝과 관리는 BPM 프로세스인가 아니면 어플리케이션 특징인가?
• 어떤 종류의 툴이 사용돼야 하는가? BPM 엔진, 작업 흐름 관리 툴, Jira와 같은 공동 작업 툴?
• 나의 loT 어플리케이션 플랫폼이 내장된 BPM 엔진을 가지고 있다면 이는 이점인가?
• 기술적인 통합은 어떤 형태를 띠는가 (Device2Process 그리고 Process2Device)?
이러한 질문들과 이에 대한 잠재적인 해답에 대해 좀 더 잘 이해하기 위해서 어떻게 프로세스 관리가 잠재적으로 loT 솔루션에 맞춰질 수 있는지 좀 더 자세히 살펴보자. 아래의 수치는 이전 장 (데이터 관리)에서의 AIA에 기반을 둔 AIA이다. 이는 결국 가장 중요한 것은 프로세스는 데이터, 사건들, 그리고 분석의 결과에 기반을 두어 작동돼야 하기 때문이다.
아래에 있는 예시에서, 우리는 한편으로는 M2M/loT 어플리케이션 플랫폼 (다음 장 참조) 또 다른 한편으로는 현존하는 기업 어플리케이션 시스템 (ERP, CRM, PLM등) 사이의 BPM/작업흐름/사례 관리 요소를 배치하였다. 우리가 Device2Process와 Process2Device라고 부르는 패턴은 자산과 장치로부터 나온 투입물에 기반을 둔 새로운 프로세스를 시작하는데 책임이 있다. 똑같은 패턴은 만약 잠재적으로 프로세스 흐름을 바꿔야 하는 장치로부터 나온 연관된 사건들이 출현한다면 현존하는 프로세스의 예를 신호화할 책임도 있다. 이와 유사하게 프로세스는 분석 엔진의 결과에 의해 시작될 수도 있다. 이러한 사용 사례는 예측 분석 알고리즘이 기계 고장이 잘 발생하게 된다는 결론에 도달하고 이러한 상황을 다루는 고객 서비스를 가질 수 있는 프로세스를 시작하는 예측 보전이 될 수도 있을 것이다.
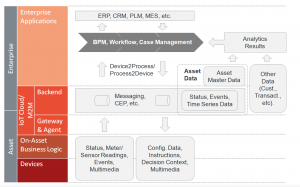 BPM, workflow, and case management in the context of the IoT
BPM, workflow, and case management in the context of the IoT
프로세스 다양성
우리가 BPM, 작업 흐름, 사례 관리를 구분 짓고 있다는 사실을 주목해보자. 이것들은 복잡한 해결방안들에서 보통 다른 보조 프로세스 혹은 매우 다른 특징들을 가지고 있는 프로세스 부분이 있다는 사실을 다루기 위해 오랫동안 개발된 세 가지 다른 개념들이다. BPM은 ERP, CRM, PLM등과 같이 다수의 후방 시스템의 조직화를 포함하는 아주 강력한 프로세스 자동화로 여겨진다. 작업 흐름 시스템은 인간 작업 흐름에 좀 더 초점을 맞추고 프로세스 자동화에는 덜 초점을 맞춘다. 마지막으로 사례 연구는 유연한 작업 흐름 관리와 같은 데이터 중심적 (“사례 폴더”) 관점을 더해주고 있다.
만약 당신이 토론의 도입부에서 다루었던 Distributed Assets Lifecycle 상의 loT의 영향력에 대해서 다시 생각해본다면, 다른 보조 프로세스의 본질을 이해하고 그들을 지원하기 위한 올바른 프로세스 관리 개념을 선택하는 것은 명백히 중요할 것이다. 예를 들어 loT 제품의 활성화는 BPM에 기반을 두어 이행될 수 있는 전형적인 고도로 자동화된 프로세스이다. 서비스 프로세스는 보통 많은 인간 간의 상호작용을 필요로 한다. 따라서 그들은 작업 흐름 관리에 의존할 것이다. 몇 가지 상황에서는 사례 관리는 지원 서비스의 흥미로운 부분이 될 수 있다. 이는 사례 관리가 관련된 데이터와 사례에 속한 맥락 정보를 수집하는 데에 매우 유용하기 때문이다. 예를 들어, 서비스 기술자는 고객 역사자료에 대한 세부적인 정보와 특정 제품에 대한 묘사를 제공하는 것뿐만 아니라 어떤 지원 운송수단과 어떤 지원 툴을 그들이 사용해야 하는지, 어떤 시간에 그들이 고객을 방문해야 하는지까지도 알려주는 정보 패키지를 얻을 수 있을 것이다.
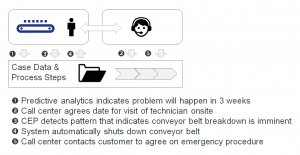
Example of complex process
마지막으로 프로세스와 사건들 사이의 지도 제작은 꽤 복잡할 수도 있고 많은 유연성을 필요로 할 수 있다. 산업상의 컨베이어 벨트를 포함하는 시나리오를 기반으로 하는 위의 예를 한번 봐보자. 이는 이전 데이터 관리 장에서 확인한 Bosch Rexroth에서 제공된 사용 사례와 유사하다. 컨베이어는 백엔드에 기계 학습 접근법을 지원하는 센서를 구비하고 있다. 하나의 주요 구성 요소에 문제가 있다는 분석 엔진 신호와 이러한 부분이 2-3주 안에 고장 날 것을 암시하는 예상을 추정해보자 (1). 콜 센터 대리인이 고객에게 접촉하는 것과 다음 2-3주 내에 예약을 잡는 등의 일을 만들어내는 프로세스 (혹은 사례, 혹은 작업 흐름)는 착수돼야 한다 (2). 이제 고객 장소에 대한 상황이 더 악화된다고 추정해보자: 우리의 CEP (Complex Event Processing) 요소는 요컨대 예측된 것보다 훨씬 상황이 빠르게 악화되었다는 상황을 의미하는 일련의 사건들과 연관성이 있다 (3). 내부적인 규칙은 이러한 상황에 기반을 두어 컨베이어 벨트가 더 이상의 손상을 피하기 위해 즉시 중단될 것임을 결정한다 (4). 프로세스는 이제 반드시 콜 센터 대리인에게 비상조치에 대해 동의하기 위해 고객들에게 긴급하게 다시 연락하도록 충고해야만 한다 (5).
이러한 시나리오는 매우 유연한 방식의 프로세스를 다룰 수 있는 loT 환경이 얼마나 중요해질 것인지 보여준다. 이것을 위한 한가지 좋은 방안은 Adaptive Case Management (ACM)이라는 사례 관리의 가장 유연한 버전을 사용하는 것이다.
전문가 의견
아래 항목에서 우리는 Opitz Consulting에서 나온 Torsten Winterberg 씨와 이 주제에 대해 이야기를 나눠 볼 것이다. Torsten 씨는 이 책의 선임 격인 Enterprise BPM에 기반을 둔 BPM 방법론을 개발하고 유지하는 Enterprise BPM Alliance (www.enterprise-bpm.org)의 매우 활동적인 구성원이다.
Dirk Slama: Torsten 씨, loT 세계에 프로세스 관리를 적용하는 것이 왜 중요한지 저희에게 설명해 주실 수 있으십니까?
Torsten Winterberg: 효과적인 프로세스 관리는 당신이 loT 프로젝트에 대해 생각해 볼 때 처음으로 생각나는 것은 아닐지도 모릅니다. 사실, 수많은 Aris 프로세스 분석가와 당신의 Arduino 전문가들을 한 방에 같이 놓는다는 것은 좋은 아이디어가 아닐 수 있을 것입니다. 하지만 저는 후방 프로세스의 진화와 큰 통신회사들의 시스템으로부터 배울 수 있는 것이 있다는 것을 믿습니다. 그들은 지난 20여 년간 마지막 고객들이 사용한 수만의 원격 장치들을 다루는 방법을 학습해왔습니다. 그들의 사업 규모를 고려해 볼 때, 그들은 차라리 일찌감치 프로세스의 효율성을 검토할 수밖에 없었습니다. 이것은 판매와 상품 배열부터 상품 활성화 고객 서비스 프로세스에 이르기까지 매우 다양한 프로세스의 종류들을 포함합니다. 바로 지금, 대부분의 loT 계획은 실제로 통합 장치와 기본 서비스 기능을 이행하는 것과 같은 기본적인 문제 해결에 초점을 맞추고 있습니다. 그러나 이러한 계획들이 규모를 키워 가면 갈수록, 그들은 똑같은 문제에 직면할 것입니다. 그들의 관련 마지막 고객들뿐만 아니라 현장의 수많은 장치들을 관리하는 것은 프리 필터링 사건들과 다른 정보들의 효과적인 방법을 찾는다는 것을 의미합니다. 이것은 자동화된 의사 결정을 도와 사업 규칙을 효율적으로 사용하고 단지 자동화될 수 없는 그러한 문제들이 인간 지원 직원에 도달함을 확신하기 위함이라고 할 수 있습니다.
Dirk Slama: BPM 사물의 측면과 장치 세계를 연결하는 가장 쉬운 방법은 무엇일까요?
Torsten Winterberg: loT 세계에서 자동화된 프로세스로부터 장점을 얻기 가장 쉬운 방법은 “흥미로운 시나리오”를 발견해내고 그러한 시나리오를 다루기 위한 프로세스를 직접적으로 적용하는 것입니다. 예를 들어 기온에 민감한 상품들이 저장되어 있는 몇몇의 창고들을 생각해 봅시다. 만약 기온 장치가 한계점을 초과한 사실을 발견한다면 이는 백엔드에 그 문제를 처리할 수 있는 프로세스를 유발할 수 있을 것입니다. 이러한 프로세스는 몇 가지의 사전 정의된 수단을 적용하는 방법으로 솔루션을 찾으려고 할 수 있습니다. 그것들이 실패한다면 사람들은 그 문제에 대해 살펴봐야 된다는 사실을 눈치챌 수 있을 것입니다. 이러한 과정이 훨씬 더 좋은 또한 훨씬 효율적인 작업 환경으로 이끌 것입니다; 고용자들은 아마 자동화된 문자 메시지 혹은 발생 전화와 같은 수단으로 편차에 대해 반응하면 될 것입니다.
Dirk Slama: 그렇군요. 매우 간단한 예시네요. 사실 좀 더 복잡합니다. 프로세스는 사례는 장치로부터 나오는 여러 가지 다른 들어오는 신호에 대해 반응해야만 할지도 모릅니다. Torsten 씨는 BPMN에 대한 이러한 문제점을 어떻게 해결할 수 있을까요?
Torsten Winterberg: 글쎄요. BPMN 엔진은 신호들을 다룰 수 있는 꽤나 괜찮은 내장된 메커니즘을 가지고 있습니다. 따라서 프로세스 사례는 많은 들어오는 사건들에 대해 대응할 수 있을 것입니다. 그러나 물론 문제를 다루는 이러한 방식이 BPMN의 전문 분야는 아닙니다. 프로세스 모델은 다른 사건들의 복잡한 사업 규칙을 통제하기 어렵게 만드는 많은 사건을 다루는 상징물들과 함께 오염되는 경향을 보이고 있습니다. 환경의 변화는 언제나 BPMN 모델의 변화를 필요로 하게 만들 것입니다. 요약해보면 이러한 시나리오의 복잡성과 환경의 변화에 대한 부족한 적응력은 BPMN 패러다임을 지나치게 긴장시키게 만들 것입니다. 그러므로 ACM이라고 불리는 BPM 규율을 사용하는 것을 저희는 추천합니다.
Dirk Slama: ACM의 의미에 대해서 좀 더 설명해주실 수 있으신가요?
Torsten Winterberg: 간략하게 ACM은 Adaptive Case Management을 의미합니다. 그리고 프로세스 모델이 너무 복잡해졌을 때, 당신이 단순히 간단한 해피 패스 모델을 가지고 있지 않을 때 혹은 당신의 좋은 BPMN 모델을 오염시킬 수 있는 많은 수의 예외 “코드”를 다룰 때 BPMN의 매우 흥미로운 대책일 것입니다. ACM은 BPMN 활동 사이의 이행에 대한 요구를 제거하고 일련의 의사 결정 규칙에 대한 이행을 대체합니다. ACM은 귀납적입니다. 예를 들어 자동차 안에 있는 네비게이션 시스템처럼 목표는 확실하나 길(프로세스 그 자체)는 불확실하고 단계적 확대들로 가득 차 있습니다. 반면 BPMN은 사전 정의된 길과 함께 있는 철도 시스템처럼 보일 수 있습니다. 만약 당신이 지름길을 원하거나 새로운 길을 원한다면 당신은 현존하는 길이나 미리 지어진 새로운 길을 사용해야 할 것입니다. IT 세계에서 “구조화되지 않은 프로세스”란 ACM의 감각이라 할 수 있을 것입니다.
Dirk Slama: 그렇다면 ACM은 구조화되지 않은 프로세스에 사용될 수 있는 규율이라고 할 수 있군요. 그러면 이것이 loT에 대해서는 어떻게 도움을 줄 수 있을까요?
Torsten Winterberg: “구조화되지 않은”이라는 용어는 보통 뭔가 혼돈 상태를 의미합니다. 하지만 여기서는 아니죠. 많은 프로세스들은 목표 중심적이거나 사례 중심적입니다. 그리고 지식 노동자들이 이러한 목표를 달성하기 위해 선택한 길은 보통 엄격하게 정의되지 않고 그들의 정보의 평가를 고려하는 것입니다. 예를 들어 의료 사례를 생각해봅시다: 환자는 병원에 들어올 것이고 몇몇의 장소에서 다양한 사람들의 전문지식에 의해 이동될 것입니다. 프로세스 관점으로 보면 환자는 병원에 들어오고 몇몇 구조화되지 않은 것들이 발생하며 최종 목표는 환자가 다시 병원을 떠나는 것이며 (물론 건강하게) 마지막으로 청구서가 보내지는 것일 겁니다.
loT의 응급상황과 함께, 이러한 사례의 종류들도 진화할 것입니다. 원격 상태 모니터링은 환자 상태와 관련된 실시간 사건들과 같은 임상 사례들에 추가적인 투입물을 제공할 수 있을 것입니다. 사용 기반 보험 (UBI)은 보험 회사들이 미래에 보험 관련 사례들을 어떻게 다룰지에 대해 영향력을 발휘할 것입니다.
ACM에서 당신은 늘 그렇듯이 지식 노동자들이 “사례”를 살펴 보기 위해 사용한 당신의 포탈에 계기판을 가지고 있습니다. UI는 지식 기반 노동자들에 의해 실행될 수 있는 근본적인 지식 기반의 현재 상태에 의해 좌우되는 그러한 활동들을 강조하고 있습니다. 통합 플랫폼과 함께 하는 공동 작업에 있는 ACM 엔진은 다른 장치의 모든 종류의 들어오는 사건들을 쉽게 수집할 수 있습니다. 이와 같이 적응 가능한 변화를 의미하면서 이러한 사건들은 근본적인 지식 기반을 바꿀 수도 있고 바꾸지 못할 수도 있습니다. 따라서 몇몇 신호 사인은 “ 녹색” 혹은 “적색”이 될 수 있으며, 들어오는 사건들에 영향을 주는 사업이 가져야만 하는 것에 따라 몇 가지 종류의 활동들은 가능하거나 불가능할 수 있습니다. 임상 사례에 대한 관계는 간단합니다. 메시지와 함께 각각의 장치들은 임상 기기 또는 다른 가치를 측정하고 의사로부터 적정한 반응을 의미하고 확정하는 임상 실험처럼 보일 수 있습니다.
Dirk Slama: 흥미로운 접근법이네요. 그런데 이러한 접근법이 BPM 세계에서 너무 복잡한 메커니즘을 소개하는 방법이 되지는 않을까요?
Torsten Winterberg: 그럴 수도 아닐 수도 있다고 말씀드려야겠네요! 시스템의 유저에게 ACM은 삶은 훨씬 쉽게 만든다고 할 수 있습니다. 이는 작업의 초점이 사업 사례에 맞춰져 있고 프로세스에서 일하는 사람이 가장 효과적인 방향으로 프로세스를 수행할 수 있는 새로운 자유를 가지고 있기 때문입니다. 다시 한번, 당신이 네비게이션 시스템을 사용하는 방법과 이것을 비교해 보십시오. 목표는 타깃 주소에 접근하는 것이지만 당신은 가능한 최선의 길을 택할 수 있는 자유를 가지고 있습니다. 대부분의 경우에 이는 명령어로 번역된 길로 주어지겠지만 확실하지 않은 환경은 유연한 반응과 길의 변화를 필요로 할지 모릅니다. 이러한 “지식 노동자”측의 사용의 용이성은 ACM 엔진 사례를 설계하는 데 있어서 더 높은 복잡성을 필요로 할 것입니다. 그러나 오늘날의 ACM 엔진들은 사업 규칙 엔진들을 통합하고 있으며 이러한 근본적인 규칙들의 투명성을 통해 더 나아지고 있습니다. 그리고 이러한 사실은 이러한 복잡성이 더 이상 큰 장애물이 아니게 만들었습니다..
Dirk Slama: 우리는 ACM이 Device2Process 솔루션을 위한 매우 귀중한 접근법이라는 것을 배웠습니다. 하지만 그 반대는요? Process2Device와의 연관성도 찾아 볼 수 있을까요
Torsten Winterberg: 사례를 성공적으로 완성하기 위해서, 당신은 아마 사례 데이터 사례 상황 그 자체를 포함하는 바깥 세계를 다루게 될 작업을 수행할지도 모릅니다. 그것들은 대체로 명확하고 안정적이기 때문에 당신은 이러한 작업 뒤에 있는 작은 BPMN 프로세스를 사용할 것입니다. 한가지 예로 피 분석은 명확하지만 피의 가치와 관련하여 나온 결과와 필요한 반응들은 명확하지 않은 것입니다. 따라서 질문은 프로세스 (BPMN에서 실행 가능한)가 위의 예와 같이 당신의 Process2Device로서의 “어떤 것”과 교류하는 것인 가능한 지입니다. 이것이 함축적으로 의미할 수 있는 것은 무엇일까요? 우리는 이것을 밝혀내기 위해 해야 할 일이 여전히 몇 가지 남아 있다는 사실을 생각해 볼 수 있습니다. 물론 프로세스는 경고 가치의 한계점을 조정하는 것과 같은 어떤 것과 상호 교류할 수 있습니다. 그러나 우리는 프로세스가 아마 단순히 사건이나 메시지를 내보낼 것 같다고 생각할 것입니다. 그리고 나서 몇몇 다른 시스템 (loT 클라우드 같은)에 의해 소비되고 결국 개별 장치들과 상호 작용을 할 것이라고 생각할 것입니다. 상황은 앞으로 몇 년간 매우 빠르게 진화할 것이고 따라서 당신의 컴퓨터 시스템의 구성은 적응 가능해야 하기 때문에, 일반적으로 당신은 당신의 프로세스와 장치 세계 사이의 지나치게 가까운 결합을 원하지는 않을 것입니다.
요컨대, 수동으로 자료를 편집하기 위해서 너무 많은 데이터와 복잡성을 갖는 것은 분석하고 반응하는 것이며 목표 중심적이고 사업 프로세스 수행하기 위해 유연한 방법을 갖는 기원은 명확한 보조 작업과 장치들의 통합을 위한 BPMN의 보조 프로세스와 함께 ACM 접근법을 위한 탄탄한 사례들을 만들 것입니다. 우리는 이러한 통합된 접근법이 오늘날 BPM 이행의 많은 결점들을 해결할 수 있기 때문에 매우 기쁩니다. 현재 거기에는 많은 수의 여전히 예측하지 못한 새로운 사업 모델들을 기대하면서 또한 크고 새로운 전문가들이 대중 데이터의 이용 가능성을 통한 기회에 영향력을 발휘할 준비가 되면서 골드러시 분위기가 다분합니다.
이 문서의 번역:
