로그인
로그인 회원가입
회원가입

BIG DATA
소개
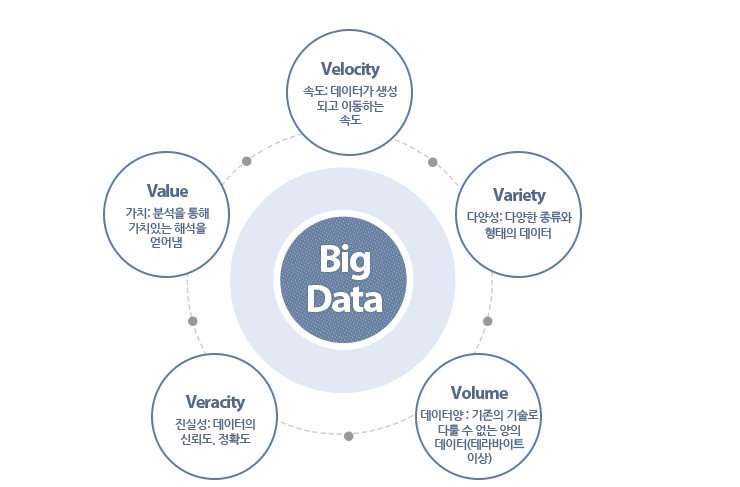
빅데이터!
일반적으로 빅데이터를 정의하는 데 있어 많은 관점이 존재 한다. 통상 빅데이터라 함은 정보를 얻기 위해 저장되고 관리되는 구조화 된 데이터, 부분 구조화된 데이터, 그리고 구조화 되어 있지 않은 데이터를 지칭한다. 단순히 데이터의 숫자만을 가지고 빅데이터를 구분하기는 어렵다. 하지만 일반적으로 페타바이트(약 100만 GB) 또는 엑사바이트(약 2의 60승) 수준의 데이터를 말한다. 지금까지 기업체나 제조현장에서 많이 사용했던 ERP나 CRM 시스템은 테라바이트 (약 1000 GB, 2의 10승) 수준의 데이터 처리 능력을 가지고 있다.
빅데이터의 발전은 구글이나 페이스북 같은 IT 기업들이 이끌어왔다. 예를 들어 구글의 엔지니어들은 데이터와 쿼리가 수 천 개의 서버로 확산될 수 있는 MapReduce의 개념을 정립하고 정교화 하였다. 이와 비슷하게 야후도 Hadoop이라는 오픈소스 빅데이터 시스템을 만들었다. 구글은 확실히 빅데이터 시장에서 한 발 앞서가고 있는 느낌이다. 최근에는 Flume과 MillWheel을 기반으로 한 차세대 빅데이터 기술인 Cloud Dataflow도 선보였다.
기술의 사용과 상관없이 빅데이터는 전통적인 RDBMS/OLAP(relational data base management system: 관계형 데이터베이스 관리 시스템 /On-Line Analytical Processing: 정보위주 분석처리) 시장으로 움직이고 있다. 다른 점이 있다면 빅데이터는 구조화 된 데이터부터 그렇지 않은 데이터까지 매우 다양하고 수 없이 많은 정보를 다루는데 특화 되어 있다는 것이다.
이런 빅데이터 기술의 기반을 바탕으로 Data Lake는 기존의 기업 데이터 수집 방식을 바꾸어 버렸다. 데이터베이스 구조를 먼저 만들고 정의한 뒤 데이터를 구조화 하는 것이 아니라, 우선적으로 아무 데이터나 무작위로 수집한 뒤 나중에 필요한 곳이 이 수집된 데이터를 적용하는 것이다.
빅데이터 분석
빅데이터 분석은 일반적으로 기술분석(descriptive)과 진단분석(diagnostic)을 포함한다. 기술통계에는 그룹화 나 데이터베이스 선별을 위한 계산, 합, 평균, 백분율, 최소 최대 값, 그리고 산술이 포함되어 있다.
몇 몇 기술자들은 사업분석의 80%가 이런 기술통계라고 주장하기도 하는데 이런 현상은 소셜미디어에서 더 뚜렷이 나타난다고 한다. 페이지 뷰, 댓글 수, 개시물 수, 팔로워, 평균 응답 빈도 등이 그 예이다.
그 이유는 사물인터넷 사업의 모든 시작이 이런 기초적인 기술통계에서 시작된다고 생각하기 때문이다.
물론 진단분석도 사물인터넷 데이터 이용에 매우 중요한 역할을 담당할 것이다. 만약 운영장치에 문제가 생긴다면, 그 문제에 대한 근본적인 원인을 찾고 분석하고 고치는데 진단분석만큼 빠르고 정확한 수단은 없기 때문이다. 현재 이 시장은 매우 커지고 있으며, 특히 여기서 다루는 스마트공장에서는 더욱 중요한 빅데이터가 될 것이다. 예를 들어 머신이나 라인의 진동 간격을이나 파동을 분석해 생산품의 불량을 잡을 수 있고, 머신의 예지보전을 할 수 있다.